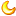|
大道至简,本文用通俗易懂的语言解释了Transformer的核心原理,针对咱们这种无基本的普通人,亦是能快速理解的,亦能对当前的大模型有更深入的认识。

过去几年中,人工智能(AI)技术的澎湃发展引领了一场前所未有的工业和科技革命。在这场革命的前沿,以OpenAI的GPT系列为表率的大型语言模型(LLM)作为了科研和应用的热点。
IDC近期颁布颁布的《全世界人工智能和生成式人工智能支出指南》表示,2022年全世界人工智能(AI)IT总投资规模为1324.9亿美元,并有望在2027年增至5124.2亿美元,年复合增长率(CAGR)为31.1%。
而带来这一轮人工智能科技革命的技术突破是来自2017年的一篇论文《Attention is All You Need》,在这篇论文中,首次提出了Transformer架构,这个架构是日前大语言模型的核心技术基本。GPT中的T便是Transformer的缩写。
下面,我先带大众简明认识下这个突破性架构的核心原理(原文:What Are Transformer Models and How Do They Work?),其实大道至简,原理无很繁杂,针对咱们这种无基本的普通人,亦是能快速理解的,亦能对当前的大模型有更深入的认识。
顺便抛出一个问题,为何这轮技术变革不是来自Google、Meta、百度阿里这般的「传统」AI强势机构,而是初创机构OpenAI引领的呢?
Transformer是设备学习中最令人兴奋的新发展之一。它们首次在论文《Attention is All You Need》中被介绍。Transformer能够用来写故事、论文、诗歌,回答问题,进行语言翻译,与人聊天,乃至能经过有些对人类来讲很难的考试!但它们到底是什么呢?你会高兴地发掘,Transformer模型的架构并不繁杂,它实质上是有些非常有用的组件的组合,每一个组件都有其特定的功能。在这篇博客文案中,你将认识所有这些组件。
这篇文案包括了一个简单的概念性介绍。倘若你想认识更加多关于Transformer模型及其工作原理的仔细描述,请查看Jay Alammar在Cohere颁布的两篇出色的文案:
The illustrated transformer 《图解Transformer》
How GPT3 works 《GPT3是怎样工作的》
简单来讲,Transformer都做些什么呢?
想象一下你在手机上写短信。每打一个词,手机可能会举荐给你三个词。例如,倘若你输入“Hello, how are”,手机可能会举荐“you”或“your”做为下一个词。当然,倘若你继续选取手机举荐的词语,你会火速发掘这些词语构成的信息毫没道理。倘若你瞧瞧每组连续的三四个词,它们可能听起来有点道理,但这些词并无连贯地构成有道理的句子。这是由于手机中的模型不会携带全部信息的上下文,它只是预测在近期的几个词之后,哪个词更可能显现。而Transformer则区别,它们能够跟踪正在写的内容的上下文,这便是为何它们写出的文本一般都是有道理的。
手机能够对短信中运用的下一个单词给出意见,但无生成连贯文本的能力
我必要得说,当我第1次发掘Transformer是一次生成一个词来构建文本的时候,我简直不敢相信。首要,这不是人类形成句子和思想的方式。咱们一般先形成一个基本的思想,而后起始细化它,添加词汇。这亦不是设备学习模型处理其他事情的方式。例如,图像的生成就不是这般的。大都数基于神经网络的图形模型会先形成图像的粗略版本,而后慢慢细化或增多细节,直到完美。那样,为何Transformer模型要一词一词地构建文本呢?一个答案是,由于这般做效果非常好。更令人满意的答案是,由于Transformer在跟踪上下文方面实在是太厉害了,因此它选取的下一个词正是继续推进一个想法所必须的。
那样,Transformer是怎样被训练的呢?必须海量的数据,实质上是互联网上的所有数据。因此,当你在Transformer输入句子“Hello, how are”时,它就晓得,基于互联网上的所有文本,最好的下一个词是“you”。倘若你给它一个更繁杂的命令,例如说,“write a story.”,它可能会想出来下一个合适的词是“Once”。而后它将这个词添加到命令中,发掘下一个合适的词是“upon”,依此类推。一词一词地,它将继续写下去,直到写出一个故事。
命令:Write a story.
回复:Once
下一个命令:Write a story. Once
回复:upon
下一个命令:Write a story. Once upon
回复:a
下一个命令:Write a story. Once upon a
回复:time
下一个命令:Write a story. Once upon a time
回复:there
等等。
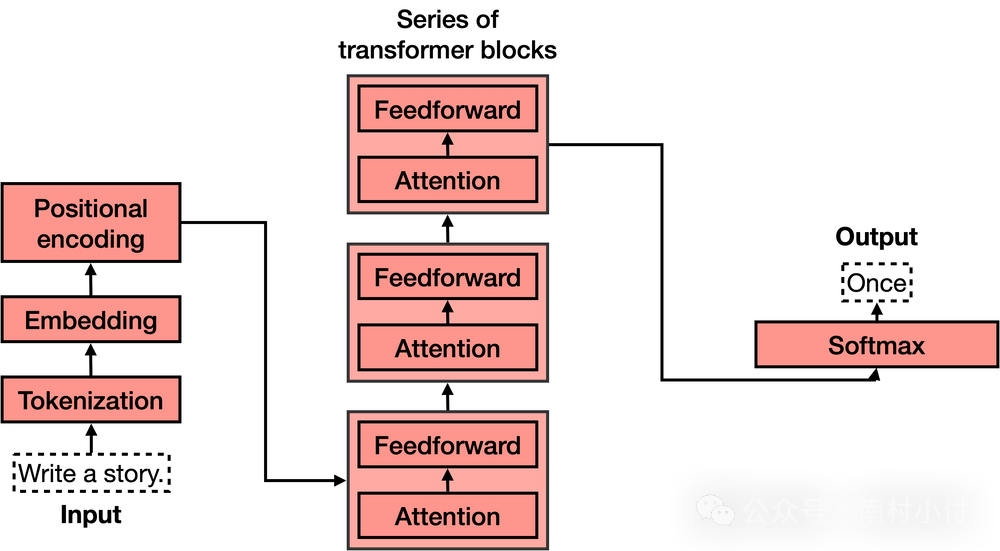
此刻咱们晓得了Transformer都做些什么,让咱们来瞧瞧它的架构。倘若你见过Transformer模型的架构,你可能像我第1次看到它时同样惊叹,它看起来相当繁杂!然而,当你把它分解成最要紧的部分时,就没那样难了。
Transformer重点有四个部分:
分词(Tokenization)
嵌入(Embedding)
位置编码(Positional encoding)
Transformer块(好几个这般的块)
Softmax
其中,第4个部分,即Transformer块,是所有部分中最繁杂的。这些块能够被连在一块,每一个块包括两个重点部分:重视力机制和前馈组件。
让咱们逐个学习这些部分。
1、Tokenization(分词)
分词是最基本的过程。它涵盖了一个庞大的词汇库,包含所有的单词、标点符号等。分词过程会处理每一个单词、前缀、后缀以及标点符号,并将它们转换为词库中已知的词汇。
举例来讲,倘若句子是“Write a story.”,那样对应的4个token将是,返回外链论坛:http://www.fok120.com/,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-7-1 00:40:11
发表于 2024-7-1 00:40:11