|
近期,《Nature Reviews Cancer》发布了一篇综述文案,全面回顾了利用大数据推进癌症科研和治疗的技术状况和将来挑战,其中包括超实用的癌症科研数据库、分析平台、科研策略等信息。
癌症科研常用资源
平常的数据类型
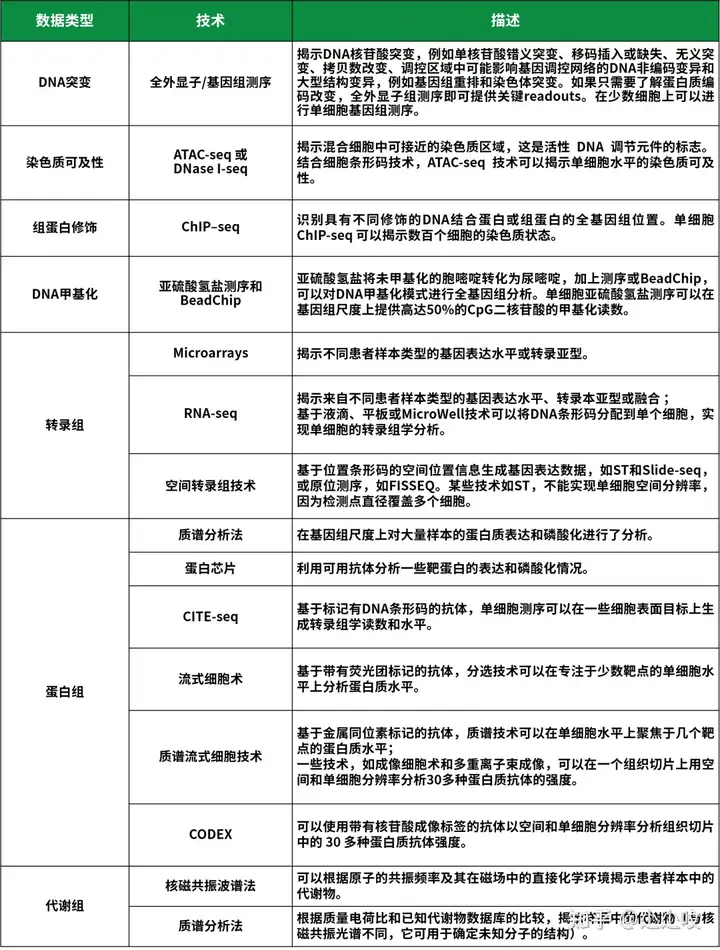
癌症科研中有五种基本数据类型:分子组学数据、微扰表型数据、分子相互功效数据、影像数据和文本数据。分子组学数据描述细胞系统和组织样本中分子的丰度或状态。这些数据是癌症科研中从病人或临床前样本中产生的最丰富类型:
癌症科研中平常的分子组学数据类型扰动表型数据描述了细胞表型,如细胞增殖或标记蛋白丰度,在基因水平或药品治疗的控制或扩增后怎样改变。平常的表型实验包含运用CRISPR敲除、干扰或激活的扰动筛选;RNA干扰;开放阅读框的过度表达;或用药品库进行治疗。做为一种限制,因为必须可遗传操作的活细胞,从临床样本中产生扰动表型数据仍然是一种挑战。
分子相互功效数据描述了分子经过与不同“伙伴”相互功效的潜在功能。平常的分子相互功效数据类型包含蛋白质-DNA相互功效、蛋白质-RNA相互作用、蛋白质-蛋白质相互功效和三维染色体相互功效的数据。与扰动表型数据类似,分子相互功效数据集一般运用细胞系生成,由于它们的生成必须海量的材料,常常超过了临床样本的数量。
诸如健康记录、组织病理学图像和放射学图像等临床数据亦拥有相当大的价值。分子组学和图像数据之间的边界不是绝对的,由于两者都能够包含其他类型的信息。
数据库和分析平台
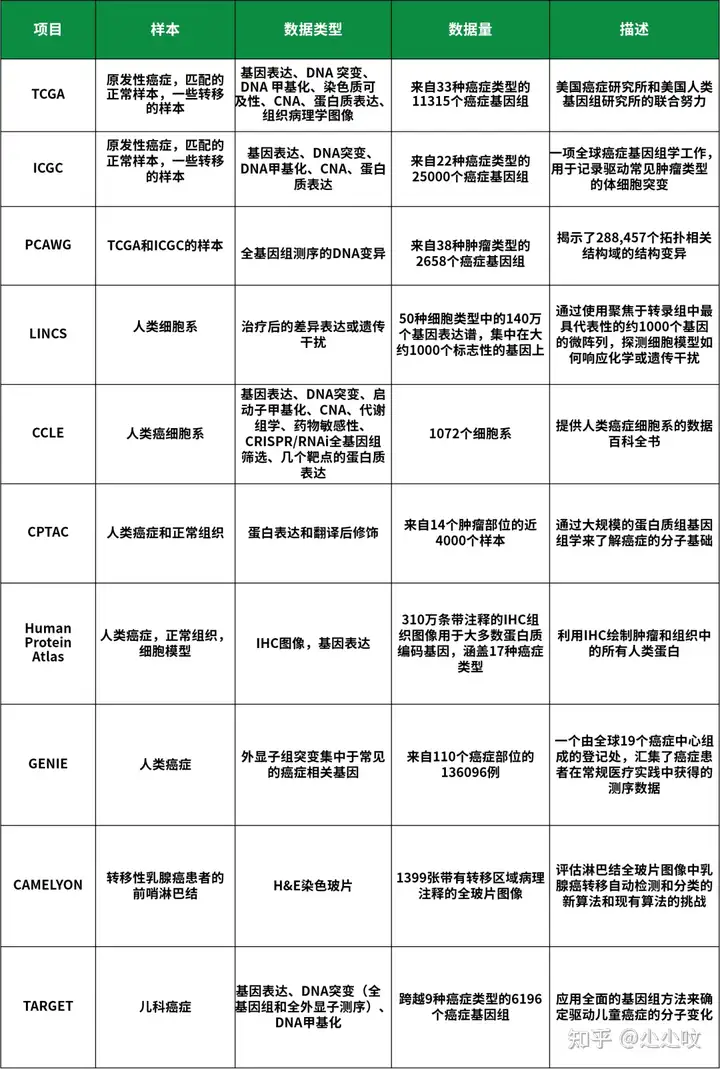
癌症科研的重要数据资源概述:1)第1类包含来自系统地产生数据的项目的资源。例如,TCGA产生了超过10,000个癌症基因组和匹配的正常样本的转录组、蛋白质组、基因组和表观基因组数据,横跨33种癌症类型。
生成癌症基因组数据集的大型项目第二类描述了展示来自以上项目的已处理数据的存储库,如Genomic Data Commons,托管TCGA数据供下载。
| 

 发表于 2024-6-26 00:34:22
发表于 2024-6-26 00:34:22