|
点击「京东数科技术说」可快速关注 
「摘要」在平常工作和生活中,写笔记、做文件备份都是非常重要的活动,咱们亦本着这般的想法,搭建了在机构内部场景下运用的笔记平台——云鸽笔记。如笔记平台的名字通常,期盼平台上的笔记能给咱们的工作带来更加多方便的信息共享、思想碰撞。
本着信息共享、实现协作的想法,咱们从用户运用场景和习惯出发,分别实现了便于工作时间快速操作的PC端、方便非工作时间快速查阅工作信息的M端,以及用来实现多人员协作的云协作。 1云鸽笔记的生态
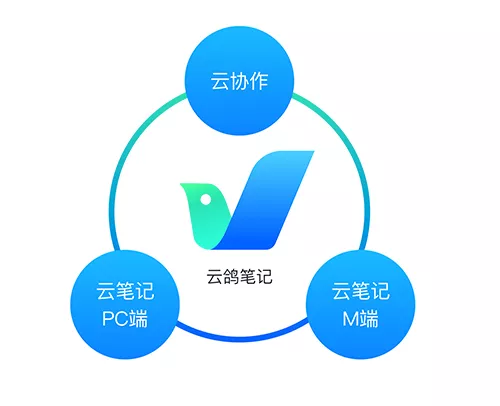
1、生态云协作:多人员协作、项目资源共享、信息同步、共享编辑、周报管理等;云鸽笔记PC端:工作时间、快速操作、随时备忘;云鸽笔记M端:非工作时间、快速查阅、随时备忘、操作轻量。2、生态图景云协作、云鸽笔记PC端
云鸽笔记M端
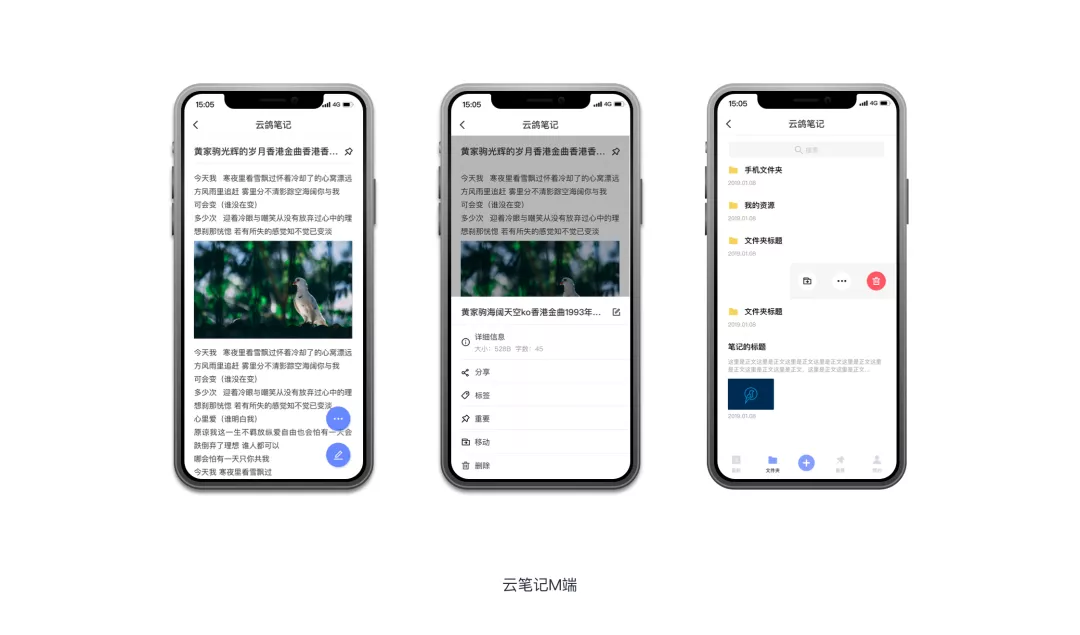
3、生态路引云鸽笔记PC端:https://yunge.jd.com云鸽笔记M端:进入“京ME”APP,应用下搜索“云鸽笔记”。如没法查到,联系@tongen。云协作:https://yunge.jd.com/team2云鸽笔记的项目管理实践践行敏捷在全部云鸽笔记的生态中,咱们践行着敏捷研发的理念,实现了小版本的快速迭代和版本更新。从大的制品来看,逐步实现云鸽笔记的PC端、M端,继而是云协作。从小的制品功能来看,咱们对制品功能进行了总体的梳理及评级,确定本期要做的功能列表。对本期功能列表进行工时与资源估算,并按照已有人员资源即时间安排,确定迭代版本的每一批功能列表。在制品实现中,咱们团队因无测试资源及严格的项目管理资源,便就现有资源做了重新分配,并灵活的将测试放在每一个版本的迭代环节里,亦充分利用了分部资源,在进行制品MVP验证的时候,同期做了必要的测试与优化提需。开发人员在每日进行功能研发时,对紧急重要的bugs放在研发计划中,进行必要的代码重构与调节。以下图示为咱们实施中的基本方式。 3云鸽笔记的设计理念随着移动办公的普及,自带设备移动办公已作为现代办公的重要形式之一。咱们本着处理私域用户工作及学习笔记的管理问题,分享和协作等场景进行设计。从制品的架构来看,咱们尽可能用简洁的设计语言,功能更加纯粹,减少有些繁杂的功能,极力降低用户的运用成本。用有效方便的操作方式让信息层级更加清晰,加强用户体验。在视觉维度,经过字体模块的体积对比及其色调明度的变化来给用户供给更加舒适的阅读和记录的线上环境。而后经过恰当的交互方式减少用户的操作成本和学习成本,缩短用户感知制品的时间,提高制品体验。4云鸽笔记的实现框架1、功能模块在这儿,咱们对现有功能模块进行了梳理和展示,重点从列表展示、内容展示、用户操作及账号同步、权限设置多方面展开。而这些功能模块的梳理亦为咱们编写框架供给了依据。 3云鸽笔记的设计理念随着移动办公的普及,自带设备移动办公已作为现代办公的重要形式之一。咱们本着处理私域用户工作及学习笔记的管理问题,分享和协作等场景进行设计。从制品的架构来看,咱们尽可能用简洁的设计语言,功能更加纯粹,减少有些繁杂的功能,极力降低用户的运用成本。用有效方便的操作方式让信息层级更加清晰,加强用户体验。在视觉维度,经过字体模块的体积对比及其色调明度的变化来给用户供给更加舒适的阅读和记录的线上环境。而后经过恰当的交互方式减少用户的操作成本和学习成本,缩短用户感知制品的时间,提高制品体验。4云鸽笔记的实现框架1、功能模块在这儿,咱们对现有功能模块进行了梳理和展示,重点从列表展示、内容展示、用户操作及账号同步、权限设置多方面展开。而这些功能模块的梳理亦为咱们编写框架供给了依据。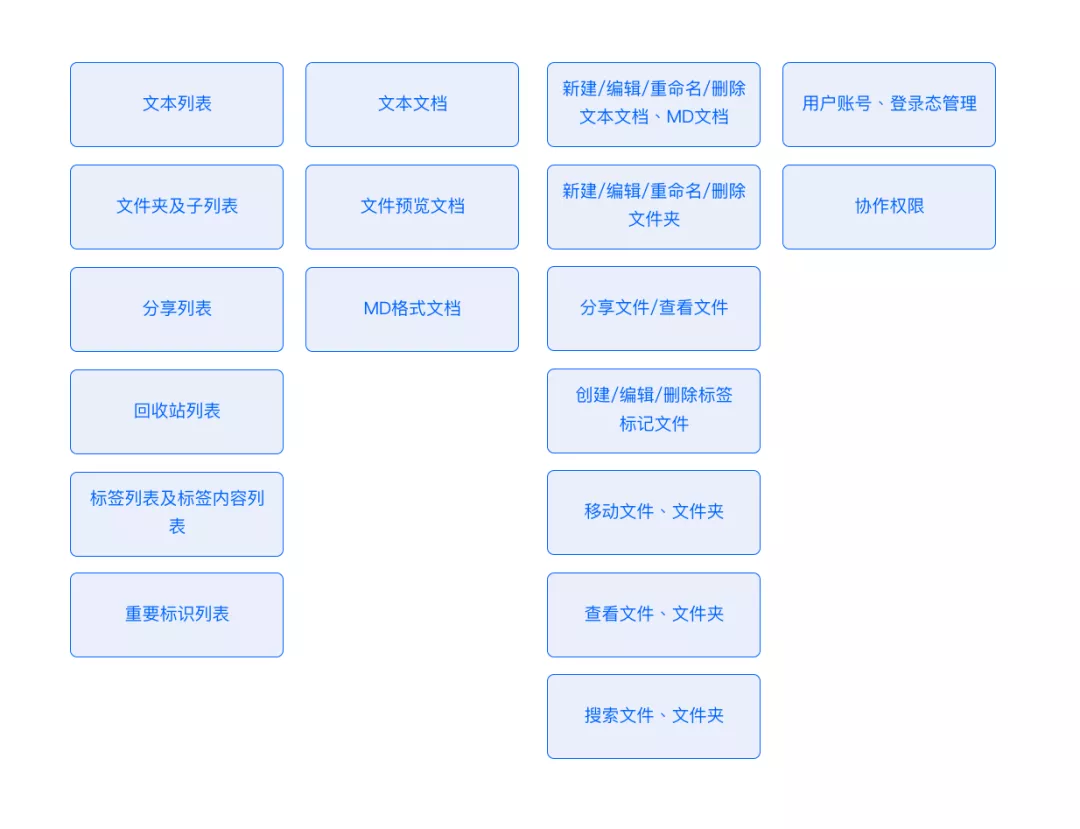  2、框架设计在框架设计中,结合功能模块的梳理,咱们遵循方便、可复用的原则,采用以下框架完成多端设计与研发。 2、框架设计在框架设计中,结合功能模块的梳理,咱们遵循方便、可复用的原则,采用以下框架完成多端设计与研发。

前端实施中,采用了React+Mobx+Typescript的技术框架,在每一个功能模块中创建其相应的Service,以用来实现应用层API的封装;在Store中实现基本数据的获取或修改,可用于PC与M两个端,而在PC和M两端,分别实现对应其操作行径的数据store。这般咱们能够达到通用store在多端的复用,又不会给每一个端带来无负作用的多余代码。在UI层面,运用Yep-React组件库,搭配构建工具Rocketact/jdwtool,有效完成项目的构建、页面研发及项目的实时预览。3、照片格式的选取由于在项目中存在各式各样的图标,它们小而多,并且会随着操作行径出现色值的改变。综合思虑,咱们选取运用SVG来掌控图标的表示,更加多原由如下:
相比传统的照片,尺寸更小,可压缩性更强
可伸缩,更清晰
方便读取和修改
设计软件直接导出 5云鸽笔记的PC端的问题与优化1、多个svg运用问题
svg的运用方式多种多样,适合自己的才是最好的。下面简单介绍下咱们的项目怎样在jdwtool脚手架中运用了svg。由于jdwtool基于webpack打包,因此webpack中必不可少需要增多针对svg的配置。代码如下: // webpack.config.js
{
test: /\.svg$/,
use: [
{ loader: path.resolve(__dirname, "./fdtsvgloader"
)
}, "svg-loader"
], include: [path.resolve(opts.baseDir, "src"
)], exclude: [path.resolve(opts.baseDir, "src/svginline"
)]
}
咱们依然运用svg-loader进行svg的处理,但svg-loader返回的是一个包括attributes和content的对象,没法直接运用。处理后的结果如下代码所示: module.exports
= {
attributes: { xmlns: http://www.w3.org/2000/svg
, viewBox: 0 0 1024 1024
}, content: <path d="M441.9 167.3l-19.8-19.8c-4.7-4.7-12.3-4.7-17 0L224 328.2 42.9 147.5c-4.7-4.7-12.3-4.7-17 0L6.1 167.3c-4.7 4.7-4.7 12.3 0 17l209.4 209.4c4.7 4.7 12.3 4.7 17 0l209.4-209.4c4.7-4.7 4.7-12.3 0-17z"/>
}
因此呢,在fdt中单独写了一个loader来得到想要的svg格式。代码如下: // fdtsvgloader.jsmodule.exports = function(source)
{ return
` ${source}
var fdtsvg = require(fdt-svg-loader)
module.exports = fdtsvg(module.exports) `
;
}; // fdt-svg-loadervar React = require("react"
); module.exports = function(svg)
{ const
content = svg.content; return function(props)
{ const newprops = { viewBox: "0 0 1024 1024", height: "20px", fill: "#000"
}; newprops.dangerouslySetInnerHTML = { __html
: content };
newprops; return React.createElement("svg"
, { ...newprops, ...props });
};
};
其中,fdtsvgloader.js中接受的参数即为svg-loader处理后的结果。最后,经过fdt-svg-loader处理后,得到了React创建的svg元素,并包括默认属性viewBox,height以及fill值。因此呢咱们在组件中能够如下方式引用svg: // demo.tsximport PptIcon from "@/image/newppt.svg"
; export default class Demo extends Component
{
render() { return <PptIcon width="18" height="18" viewBox="0 0 27 34" />
;
} }
demo中传递的属性便可覆盖默认属性,灵活掌控svg的体积。至此,咱们在项目中愉快的运用svg来掌控各式各样图标的表示。
然则忽然有一天,在一个慵懒的午后,测试朋友忽然告诉我,页面中的图标从左边变成为了右边的样子。短暂的惊慌之后,我快速抄起键盘寻找bug的所在之处。
实不相瞒,在做此项目之前,我较少涉猎svg的知识,针对svg并不是很熟练。因此呢,寻找bug的过程中遇到了有些困难和挫折。在较短的时间内并无快速找到问题所在,首要想到的是重新更换一下图标(设计软件中导出的图标咱们做过手动处理)。惊奇的发掘,这个办法居然好用,果断完成上线。事后慢慢琢磨这个事情,一个svg照片并无受到外边CSS的影响,为何会忽然引起问题呢?为了更快的发掘问题,我仔细科研了一下咱们的svg图标的结构,学到了有些关于svg的内容:<g>该标签表率组合<defs>定义重用图形<polygon>定义多边形<mask>定义蒙层<use>实现SVG现有图形的重用
既然没法直接找到答案,那只好上排除法来寻找问题所在了。最后发掘,问题显现的原由是新引入的图标影响了原有图标。svg互相影响亦真的让我非常震惊。
那到底是怎么互相影响的呢?原由便是新的图标中定义了一个mask蒙层,属性id为mask-2。受影响的图标中,path标签的mask属性引用了该mask-2的蒙层,引起新图标的显现影响了部分旧图标。
那样针对直接在html中引入svg,浏览器针对重用图标的寻找机制是怎么样的呢?咱们做了如下测试: <svg width="400" height="300"> <defs> <linearGradient id=white2black> <stop offset="0" stop-color="white"></stop> <stop offset="100%" stop-color="black"></stop> </linearGradient> <mask id="opacity"> <rect x="0" y="0" width="400" height="300" fill="url(#white2black)"></rect> </mask> </defs> <rect id="back" x="0" y="0" width="400" height="300" fill="#d4fcff"></rect> <rect id="front" x="0" y="0" width="400" height="300" fill="#fcd3db" mask="url(#opacity)"></rect> </svg> <svg width="600" height="300"> <defs> <linearGradient id=white2black> <stop offset="0" stop-color="blue"></stop> <stop offset="50%" stop-color="black"></stop> <stop offset="100%" stop-color="green"></stop> </linearGradient> <mask id="opacity"> <rect x="50" y="0" width="600" height="400" fill="green"></rect> </mask> </defs> <rect id="back" x="0" y="0" width="400" height="300" fill="#d4fcff"></rect> <rect id="front" x="0" y="0" width="400" height="300" fill="#fcd3db" mask="url(#opacity)"></rect> </svg>
该代码的展示效果为:

当把第1个svg的mask标签删除之后 <svg width="400" height="300"> <defs> <linearGradient id=white2black> <stop offset="0" stop-color="white"></stop> <stop offset="100%" stop-color="black"></stop> </linearGradient> </defs> <rect id="back" x="0" y="0" width="400" height="300" fill="#d4fcff"></rect> <rect id="front" x="0" y="0" width="400" height="300" fill="#fcd3db" mask="url(#opacity)"></rect> </svg> <svg width="600" height="300"> <defs> <linearGradient id=white2black> <stop offset="0" stop-color="blue"></stop> <stop offset="50%" stop-color="black"></stop> <stop offset="100%" stop-color="green"></stop> </linearGradient> <mask id="opacity"> <rect x="50" y="0" width="600" height="400" fill="green"></rect> </mask> </defs> <rect id="back" x="0" y="0" width="400" height="300" fill="#d4fcff"></rect> <rect id="front" x="0" y="0" width="400" height="300" fill="#fcd3db" mask="url(#opacity)"></rect> </svg>
效果变为:

由此能够判断,svg在寻找重用元素时的机制为:在当前HTML环境中寻找第1个匹配的元素。并不是想象中的在svg自己内部寻找或逐层往外寻找。因此,在html中直接引入svg必然会存在互相影响的问题,亦必然会带来有些未知的危害。那样到底有无较为安全的方法呢?办法总比困难多,处理方法肯定是存在的。为了防止互相影响,咱们运用css中的bac公斤round-image属性将svg引入,该方法中的svg在寻找重用元素时,仅仅会寻找自己标签内是不是存在,而不会向外寻找,因此呢必定程度上保准了svg图标的安全性。那以后要始终运用该种方法吗?我觉得还是分场景运用最为合适。例如:一成不变的svg图标能够采用css的方式引入,带有交互行径的图标能够采用html的方式引入,方便修改样式。当然,最重要的便是,针对直接运用的图标,svg内最好干净的仅剩下path标签,这般不会带来任何问题。当然,svg sprites运用use引用时亦会存在问题。2、第三方库引用新姿势众所周知,React本身举荐两种引用办法,一种是经过HTML的script标签引入React,另一种是运用例如Create-react-app等脚手架起步大型React应用。前者是将React集成到现有项目最简单的方式,而大都数人在运用React框架的时候,常常选取后者,由于后者更方便扩展文件和组件的规模,运用npm的第三方库。此时,咱们需要将React安装在项目的node_modules中,并写入package.json文件的dependence字段,并运用yarn.lock锁住版本。这般,当多人协作完成项目或更换设备初始化代码时都会将因此依赖根据锁定的版本安装,保准项目的正常运行。这是一种很广泛、很平常的用法,详细内容无需赘述。这里,仅介绍一下咱们的运用办法。运用script的方式引入React:  fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
项目中依然运用:
同期并不将React安装到项目依赖中。看到这非常多人会问,编辑器不会提示找不到react吗?我给出你的答案肯定是不会。
为何呢?由于脚手架jdwtool做了一步处理。大家都晓得,import寻找依赖的机制是从当前项目中的node_module起始,依次往父级查询,最后查询到系统目录,倘若这里过程中完成匹配,那查询到此为止。显然,引入的react并不会查询到,由于在系统目录亦并未安装,那样到底怎么查询到的呢?这个就需要 tsconfig path 来为咱们助力了。使用tsconfig中的path字段进行路径映射,当项目中没法匹配到依赖时,会根据path中给出的字段进行匹配,直到匹配完成。动态生成的path如下:
其中,映射的路径为xyz,先从x起始,直到z匹配完成。这儿面包括了jdwtool的安装路径,将React安装到了jdwtool的node_modules下。因此呢,项目中import react时,可从jdwtool的node_modules下查询到react,保准项目的正常运行。
下面,能够看一下项目的dependence字段:
从图中能够看到,项目中并不会安装有些通用的依赖,所有通用的依赖都安装到了jdwtool下,这便是咱们整体的实现思路。
这么做到底有什么好处呢?
一次加载,多处运用。加载一次cdn上的react文件,任何请求该文件的项目都可走缓存,而无需请求。
方便升级react版本。大众都晓得,react总会给咱们带来非常多惊喜,尝试新版本总是变的迫不及待。运用这种办法,能够容易升级react版本,而无需担心重新打包vendor。
脚手架安装依赖,项目初始化更快。非常多的依赖都安装在了脚手架中,那样项目中安装的依赖变的非常少,这使得每一个人clone下项目后,无需花费太多的时间等待依赖的安装。
脚手架统一升级依赖版本。依赖都安装在脚手架的安装目录下,当需要升级依赖版本时,只需要更新脚手架就可。 看到这亦许有人会问,假如某个项目不想运用脚手架的依赖怎么办?这个只需要在项目中安装指定版本的依赖就可。那样为何不将antd运用script的方式引入呢?由于antd咱们运用了按需加载,而不像react这种全量加载。因此呢,针对需要全量加载的依赖,能够尝试运用这种方式引入。3、antd icons 按需加载前文咱们说到过,针对antd这种能够按需加载组件的库,不运用script的方式全量引入。确实,antd支持按需加载组件。实现按需加载组件的方式有两种,一种是单个组件分别引入对应的组件与样式,这种方式代码冗余,因此呢更加多人爱好第二种运用babel-plugin-import的方式实现按需加载。第二种详细的实现方式网上案例较多,脚手架亦加入了对antd按需加载的处理,但这不是本段的主旨,本段的主旨是介绍antd中Icon组件的按需加载。事情的起因是这般的,咱们引用了一个Icon下的一个图标,而后看了下打包后的体积,发掘增大了好多。于是查看了打包后的内容发掘,antd将所有的Icon的导入了。。。都导入了。。看一下antd中Icon组件的源码,其中最引入注目的肯定是这段代码:
当调用antd的Icon组件时,会将所有的Icon导入。其实所有导入亦没什么,关键是看一下dist的体积,500kb+。运用了一个Icon需要增大500kb的体积,这显然并不合适。因此呢,咱们要寻找一种处理方法。首要,在工具类目下创建一个文件,名为icons.ts,内容如下:icons.ts中咱们默认导出了两个需要运用的图标,况且项目中业仅仅运用了这两个图标。假如想运用更加多的图标,那样亦能够在该文件中写入。其次,webpack设置别名alias。由于脚手架中的webpack配置均从toml文件中读取。因此,需要在toml中配置webpack的alias,代码如下:第三,在项目中正常运用Icon。这般一来,当引入Icon时,就把本来要引用的dist指向了自己写的icons.ts。无需所有加载!避免运用一个Icon带来500kb网络开销的包袱。6云鸽笔记的M端的技术难点解析1、滚动列表的实现在M端起始进入研发时,PC端已基本完成。同步PC端的代码库,科研列表发掘,使用了持有虚拟滚动条的 InfiniteLoader 的代码库;在M端尝试运用该库,发掘生成的页面层级过深,页面较繁杂,虽虚拟滚动条看起来会顺畅,咱们最后放弃了在M端的应用。不外咱们还是对 InfiniteLoader 做了进一步理解和尝试。例如怎样动态设置行高,怎样屏蔽在首屏数据未加载的状况下唤起下一次数据请求。来一波伪代码:<InfiniteLoader isRowLoaded={isRowLoaded} loadMoreRows={loadmore} rowCount={count} threshold={10} minimumBatchSize={20} >
{({ onRowsRendered, registerChild }) => ( <AutoSizer>
{({ height, width }) => ( <List ref={registerChild} onRowsRendered={onRowsRendered} deferredMeasurementCache={cache} rowHeight={cache.rowHeight} rowRenderer={rowRenderer} />
)} </AutoSizer>
)} </InfiniteLoader>const rowRenderer = ({ key, index, style, parent }) =>
{ return
( <CellMeasurer cache={cache} columnIndex={0} key={key} parent={parent} rowIndex={index} > <div className="infinitelist-item" > </div> </CellMeasurer>
)
}; 其中 CellMeasurer 组件能够实现动态设置元素行高;而threshold 、minimumBatchSize 和 defaultHeight等混合应用才可处理不要在首屏首次列表数据未加载完毕时发起再次请求的问题。2、列表页面切换保持切换前滚动高度页面在切换时,能保持原页面的滚动高度,能够大大提高用户体验,不会让用户因在切换之间页面跳来跳去,有失去控制的感觉。还是回到刚才的 InfiniteLoader 组件,很强大,供给了上一个页面离开时的滚动高度。不外由于已废弃掉该组件在项目中的应用,需要自己来实现。不如把页面滚动和页面转间的关系画下来,按图索骥,便会一目了然。上图已比较清晰的展示了页面滚动及页面转,只需找个地区把转前页面的scrolltop值存储下来,等再次回到该页面是,再取来去做转就好了。以下是伪代码展示:// 写
setScrollTopByPager(page: string, top: number) { this
.topHash | 

 发表于 2024-10-3 11:01:10
发表于 2024-10-3 11:01:10