程序员的困境
程序员在工作中常常面临着许多困境,其中之一便是难以恰当证明自己的价值。在软件研发过程中,程序员们投入了海量的时间和精力,编写繁杂的代码以实现各样功能。然而,针对哪些不熟练编程的业务人员和管理人员来讲,代码如同一个奥秘的黑匣子,她们难以理解其中的价值。
这一困境的产生有多方面的原由。首要,编程是一项高度专业化的工作,需要把握特定的编程语言、算法和数据结构等知识。针对非技术人员来讲,这些知识常常超出了她们的理解范围。其次,代码的价值常常难以直接衡量。不像有些传统行业的工作成果能够经过详细的制品数量、营销额等指标来衡量,代码的价值更加多地表现在其对业务的支持程度、系统的稳定性和性能等方面。这些指标常常较为抽象,难以直观地呈现给业务人员和管理人员。
为认识决这一困境,需要一个业务、技术双方都看得懂、都认可的衡量维度。
代码当量做为一种客观的度量维度,恰好能够满足这一需要。代码当量基于抽象语法树繁杂度的计算,不受编程习惯和特定代码行径的干扰,能够准确地反映代码研发所触及的规律量和工作量。针对技术人员来讲,代码当量能够做为衡量自己工作成果的重要指标,让她们更有底气地展示自己在项目中的价值。针对业务人员和管理人员来讲,代码当量供给了一个相对直观的衡量标准,使她们能够更好地理解代码的价值和程序员的贡献。
代码当量:开启程序员度量新视角

代码当量做为一种新的度量指标,为程序员的工作评定带来了全新的视角。与传统的代码行数指标相比,代码当量拥有明显的优良。传统的代码行数指标缺乏统一标准,区别的编程语言、编程风格和注释方式都会影响其统计结果,使得区别项目之间的比较变得困难。况且代码行数只是表面上的量化指标,不可真正反映代码的繁杂性和价值。
例如,在一个真实的案例中,Bitcoin 项目中一个名为 Fix CRLF 的提交,修改了 62 个文件,删除了 32876 行代码,又将这 32876 行加了回去。从代码行数的方向看,这是一个体量相当巨大的修改,但实质上对代码无任何改动。而这个提交的代码当量为 0。
代码当量基于抽象语法树繁杂度的计算,很难受到编程习惯或特定代码行径的干扰,如换行、空行、注释、括号等。同期,它能更好地反映代码研发所触及的规律量。经过为每一个 AST 节点类型分配区别的权重,能够对区别类型 AST 节点的编辑操作进行更恰当的评定,更恰当地量化研发过程中的工作量。
深入剖析代码当量
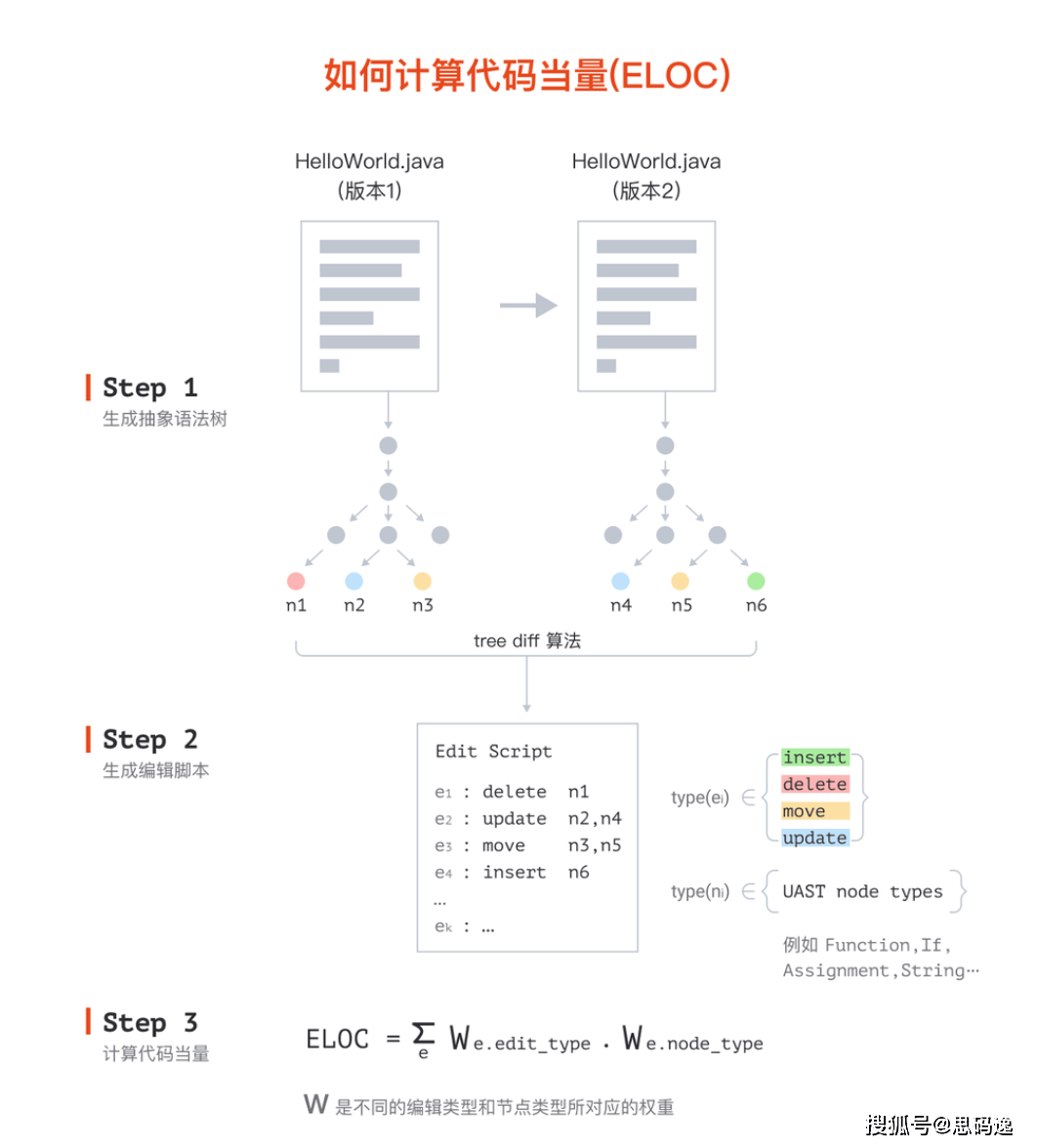
代码当量的源自与原理
代码当量指标基于抽象语法树繁杂度的计算,其原型来自思码逸2018 年在软件工程顶级会议 FSE 上发布的论文《关于量化代码贡献的研发价值》。软件研发是一个动态的过程,代码随着提交出现变化,相应的抽象语法树亦会演变,代码当量正是基于这种演变进行计算。它思虑了抽象语法树的节点数、区别节点的权重等原因,能够更准确地反映研发者代码工作量。
代码当量的计算办法
代码当量的计算过程分为三步。首要,将源代码解析为抽象语法树(AST),AST 是源代码抽象语法结构的树型暗示,其 “抽象” 性质有助于消除测绘中不重要的噪音。例如,在代码修改前后的抽象语法树对比中能够看出,纯句法变化对 AST 无影响,从而避免了因简单的代码格式变动而引起的工作量误判。其次,计算新旧树之间的树的差异(树 diff),树 diff 过程的输出是一个编辑脚本,由一系列编辑操作构成,包含插进、删除、移动和更新等类型。最后,计算所有编辑操作的加权总和,按照编辑操作的类型和此编辑操作的 AST 节点的类型为每一个操作分配权重,最后得到代码当量的数值。
代码当量的优良表现
相比代码行数,代码当量拥有显著优良。例如代码行数指标很容易被简单的代码习惯差异所影响,如删除红色代码,新增绿色代码,实质上只是简单的代码格式变动,并不实质改变基本规律和代码质量,却表现为多行更改,而代码当量这里状况下为 0。代码行数亦不善于检测代码块的移动,例如交换类中函数的次序会产生多行添加和删除,但从抽象语法树方向看,节点本身未出现任何修改,代码当量亦为 0。另外,代码行数没法区分区别性质的代码的工作量,而经过为每一个 AST 节点类型分配区别的权重,代码当量能够对区别类型 AST 节点的编辑操作进行更恰当的评定,更恰当地量化研发过程中的工作量。
代码当量与程序员话语体系
客观度量带来的话语基本
代码当量做为一个客观的度量维度,为程序员构建话语体系供给了坚实的基本。在传统的工作评定中,缺乏一个统一且客观的标准,使得程序员在表达自己的工作成果和价值时常常面临困境。而代码当量的显现,改变了这一局面。它基于抽象语法树繁杂度的计算,不受编程习惯和特定代码行径的干扰,能够准确地反映代码研发所触及的规律量和工作量。
例如,当程序员在讨论项目进度和个人贡献时,能够用代码当量来详细说明自己完成的工作。一个拥有较高代码当量的程序员,能够更有底气地展示自己在项目中的重要性和价值。同期,代码当量亦为项目管理者供给了一个客观的评定标准,使得她们在分配任务、评定绩效时更加公正恰当。这有助于减少因主观评估而产生的争议,为程序员构建起一个以客观数据为支撑的话语体系。
按照搜索到的资料,人均生产率计算公式为:人均代码当量 = 统计周期内相应步长总代码当量 / 代码提交者数。这一公式进一步知道了代码当量在团队层面的应用,为程序员在团队中的地位和贡献供给了量化的依据。
促进交流与合作
代码当量还有助于程序员在团队中更准确地交流工作成果,促进合作。在软件研发过程中,团队成员之间的沟通和协作至关重要。然而,因为缺乏统一的度量标准,程序员之间常常难以准确理解彼此的工作进度和贡献。
代码当量的显现,为程序员供给了一个一起的语言。当程序员讨论代码修改、功能实现等问题时,能够用代码当量来描述工作量和繁杂度。例如,一个程序员能够说:“我这次的代码修改增多了 X 个代码当量,重点是优化了算法,减少了运行时间。” 这般的表述能够让其他团队成员更直观地认识工作成果,从而更好地进行协作。
另外,代码当量还能够促进团队之间的交流与学习。经过比较区别团队的代码当量,程序员能够认识到其他团队的工作方式和技术水平,从而借鉴经验,加强自己的能力。同期,团队管理者亦能够按照代码当量的分析结果,合理调节团队结构和任务分配,加强团队的整体效率。
程序员怎样利用代码当量构建话语体系
以代码当量为核心的工作方式
程序员能够将代码当量做为核心指标,融入到平常工作的各个环节中,以提高工作质量和效率。在任务规划周期,程序员能够按照项目需要和自己能力,预估所需完成的代码当量。例如,在接手一个新的功能模块研发任务时,经过分析类似功能的代码当量历史数据,恰当估算自己需要投入的工作量和时间。在研发过程中,时刻关注自己的代码当量产出,保证工作进度符合预期。倘若发掘代码当量增长缓慢,能够即时反思研发办法是不是有效,是不是存在能够优化的地区。例如,经过引入更简洁的算法或优化代码结构,加强代码当量的产出效率。同期,程序员还能够利用代码当量来评定自己的代码质量。较高的代码当量并不必定寓意着高质量的代码,还需要结合代码的可读性、可守护性等原因进行综合考量。例如,倘若为了追求高代码当量而采用繁杂的代码结构,可能会引起后续守护成本增多。因此呢,程序员在追求代码当量的同期,亦要注重代码的质量和可守护性。
在团队协作中的应用
在团队协作中,代码当量能够帮忙程序员更好地沟通和协调。首要,在任务分配环节,团队管理者能够按照成员的能力和经验,恰当分配代码当量任务。例如,针对经验丰富的程序员,能够分配较高代码当量的繁杂任务;针对新手程序员,能够分配相对较低代码当量的简单任务。这般能够保证团队成员的工作量平衡,加强整体工作效率。在项目进度跟踪方面,团队能够定时统计代码当量的完成状况,认识项目的发展状态。倘若发掘某个成员的代码当量完成进度滞后,能够即时进行沟通和协调,找出问题所在并采取相应的办法。另外,代码当量还能够用于团队内部的技术交流和分享。例如,当一个成员完成为了一项拥有较高代码当量的任务时,能够在团队内部进行分享,介绍自己的研发思路和技术办法,帮忙其他成员加强技术水平。
对将来编程工作的影响
展望将来,代码当量将对程序员的工作方式和话语体系产生深远的影响。随着软件工程分析技术的持续发展,代码当量的计算办法将更加精细和智能化。程序员能够经过实时的代码当量分析,即时认识自己的工作效率和质量,从而进行针对性的调节和优化。在远程办公和智能化编程的趋势下,代码当量将作为衡量程序员工作成果的重要指标。例如,在远程团队协作中,代码当量能够帮忙团队成员更好地认识彼此的工作进度和贡献,减少沟通成本和误解。同期,代码当量亦将推动程序员更加注重自己技术能力的提高。为了加强代码当量的产出效率,程序员需要持续学习新的编程技术和办法,加强自己的编程水平。这将促进程序员行业形成一个更加注重技术实力和工作效率的话语体系。返回外链论坛: http://www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-10-3 04:24:38
发表于 2024-10-3 04:24:38

