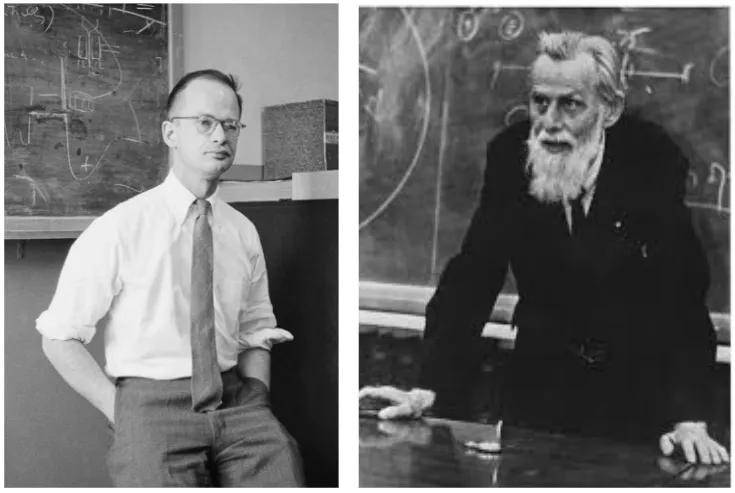|
近期这两年,随着AIGC大模型的崛起,全部社会掀起了一股强劲的AI浪潮。
人们在关注AI,企业在拥抱AI,资本在追逐AI。凡是和AI相关的概念,都会吸引海量的目光。
那样,AI是怎样循序渐进步行到今天的呢?它经历了那些发展周期,又出现过那些精彩的故事?
今天这篇文案,咱们就来仔细回顾一下,人类AI的发展历程。
█ 萌芽周期
人类对人造智能体的追求和畅想,最早能够追溯到古希腊时代。
在古希腊神话中,火与工匠之神赫菲斯托斯,曾经制作了一组金制的女设备人,“有心能解意,有嘴能说话,有手能使力,精通手工制造”。
在中国的古代史籍中,亦显现过“人工智能”的影子。
《列子·汤问篇》中,偃师向周穆王进献了一个机械人,会唱歌、会跳舞,还会挑逗周穆王的嫔妃。周穆王醋意爆发,认为机械人是真人假扮,要杀掉偃师。偃师赶紧将机械人拆散,周穆公才罢休。
上面的这些文字记载,显然都不可靠。在遥远且漫长的古代,以人类当时的技术水平,肯定是造不出智能体的。能造出有些简单的机械(例如诸葛亮的木牛流马),都已然很了不起了。
人们对智能体的寄望,很多都依托于鬼神等宗教信仰——将人的灵魂附身于机械,才可够实现“人工智能”。
到了近现代,随着工业革命的爆发,人类起始逐步进入机械计算、电气计算时代。计算能力的持续增长,使得经过“算力”来驱动“智能”,作为一种可行选项。
17世纪,莱布尼茨、托马斯·霍布斯和笛卡儿等率先提出:是不是能够将人类理性的思考系统,转化为代数学或几何学体系?
莱布尼茨认为:“人类的思想,能够简化成某种运算。”
霍布斯亦提出:“推理便是计算。”
这些伟大的思想,为后来的计算机和人工智能发展指明了方向。
再后面的事情,大众都比较清楚了——
在查尔斯·巴贝奇(Charles Babbage)的分析机、赫尔曼·何乐礼(Herman Hollerith)的制表机、阿兰·图灵(Alan Turing)的图灵机,以及Z3、珍妮机、Mark I、ENIAC等一系列发明的接力推动下,人类最终进入了数字电子计算机时代,亦开启了波涛壮阔的信息技术革命。(不清楚的,看这儿:算力简史)
█ 第1次高潮周期(1950年-1973年) 图灵测试
数字电子计算机正式诞生之后,火速就有专家起始探索,是不是能够经过计算机来实现“智能”。
1950年,阿兰·图灵在《心灵(Mind)》杂志上发布了一篇非常重要的论文,名叫《计算设备与智能(Computing Machinery and Intelligence)》。
 阿兰·图灵(1912-1954) 阿兰·图灵(1912-1954)
在论文开头,他就提出了一个灵魂之问:
“I propose to consider the question, ‘Can machines think?’"
“我提议思考这般一个问题:‘设备能够思考吗?’”
图灵在论文中仔细讨论了创造“智能设备”的可能性。因为“智能”一词很难定义,他提出了著名的图灵测试(以下为大致意思):
“一个人在不接触对方的状况下,经过一种特殊的方式和对方进行一系列的问答。倘若在相当长期内,他没法按照这些问题判断对方是人还是计算机,那样,就能够认为这个计算机是智能的。”
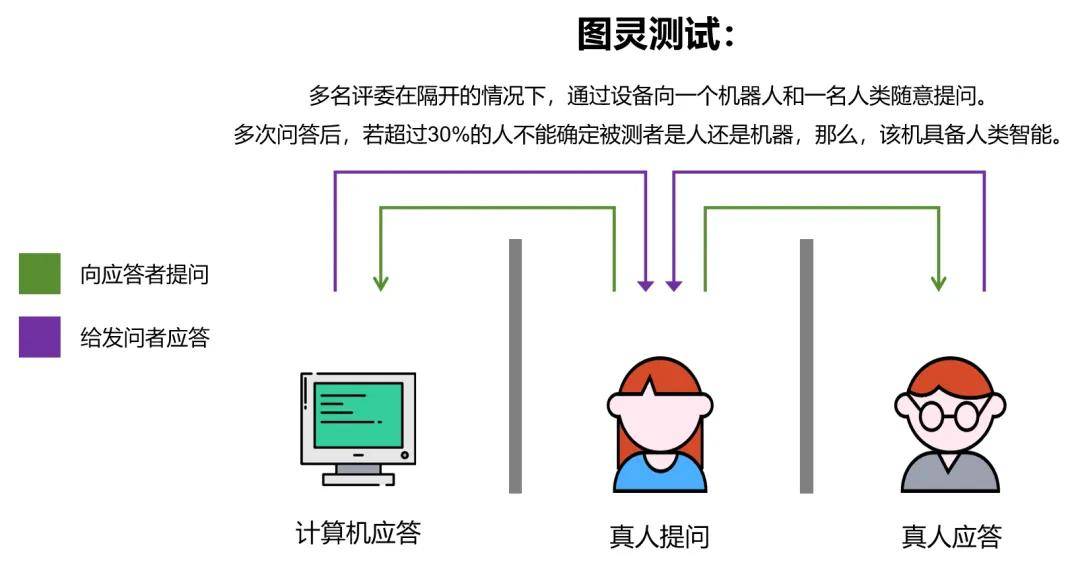 图灵测试 图灵测试
图灵的论文,在学术界导致了广泛的反响。越来越多的学者被这个专题所吸引,参与到对“设备智能”的科研之中。其中,就包含达特茅斯学院的青年数学助教约翰·麦卡锡(J. McCarthy),以及哈佛大学的青年数学和神经学家马文·明斯基(M. L. Minsky)。 达特茅斯会议
1955年9月,约翰·麦卡锡、马文·明斯基、克劳德·香农(C. E. Shannon)、纳撒尼尔·罗切斯特(N. Rochester)四人,一起提出了一个关于设备智能的科研项目。在项目中,首次引入了“Artificial Intelligence”这个词,亦便是人工智能。
1956年6月,在刚才那4个人的召集下,在洛克菲勒基金会的帮助下,十余位来自区别行业的专家,聚集在美国新罕布什尔州汉诺威镇的达特茅斯学院,召开了一场为期将近两月的学术研讨会,专门讨论设备智能。
这次研讨会,便是著名的达特茅斯会议(Dartmouth workshop)。
 参加会议的部分大佬 参加会议的部分大佬
达特茅斯会议并无得出什么重要的结论或宣言,然则认可了“人工智能(Artificial Intelligence)”的命名,亦大致知道了后续的科研方向。
这次会议,标志着人工智能做为一个科研行业正式诞生,亦被后人视为现代人工智能的起点。 AI三大学派
达特茅斯会议之后,人工智能进入了一个快速发展周期。参与科研的人变得更加多了,况且,亦逐步形成为了几大学术派系。
在这儿,咱们要说到人工智能最著名的三大学派——符号主义、联结主义(亦叫联接主义、连结主义)、行径主义。

符号主义是当时最主流的一个学派。
她们认为,世界中的实体、概念以及它们之间的关系,都能够用符号来暗示。人类思维的基本单元,亦是符号。倘若计算机能像人脑同样,接收符号输入,对符号进行操作处理,而后产生符号输出,就能够表现出智能。
这个思路,关键在于把知识进行编码,形成一个知识库,而后经过推理引擎和规则系统,进行推断,以此处理繁杂的问题。
符号主义初期的表率性成果,是1955年赫伯特·西蒙(Herbert A. Simon,亦译为司马贺)和艾伦·纽维尔(Allen Newell)研发的一个名为“规律理论家(Logic Theorist)”的程序。
“规律理论家”被认为是人类历史上第1个人工智能程序,并且在达特茅斯会议上进行了演示。它将每一个问题都暗示成一个树形模型,而后选取最可能得到正确结论的那条线,来求解问题。
1957年,赫伯特·西蒙等人在“规律理论家”的基本上,又推出了通用问题处理器(General Problem Solver,GPS),亦是符号主义的初期表率。
进入1960年代,符号主义亦进入了一个鼎盛时期。在自然语言理解、微世界推理、专家系统(重视这个词,后面会再次说到它)等行业,人工智能取得了突破性的发展,亦逐步作为公众关注的对象。
1958年,约翰·麦卡锡正式发布了自己研发的人工智能编程语言——LISP(LIST PROCESSING,意思是"表处理")。后来的非常多知名AI程序,都是基于LISP研发的。
 约翰·麦卡锡(1927-2011) 约翰·麦卡锡(1927-2011)
1966年,美国麻省理工学院的魏泽鲍姆(Joseph Weizenbaum),发布了世界上第1个聊天设备人——ELIZA。
ELIZA的名字源于萧伯纳戏剧作品《卖花女》中的主角名。它仅有200行程序代码和一个有限的对话库,能够针对提问中的关键词,进行答复。
ELIZA其实无任何智能性可言。它基于规则运作,既不睬解对方的内容,亦不晓得自己在说什么。但即便如此,它还是在当时导致了轰动。ELIZA能够说是此刻Siri、小爱朋友等问答交互工具的鼻祖。
 魏泽鲍姆(坐者)正在与ELIZA对话 魏泽鲍姆(坐者)正在与ELIZA对话
再来瞧瞧联结主义。
联结主义,强调模仿人脑的工作原理,创立神经元之间的联结模型,以此实现人工神经运算。
大众可能会有点激动。没错,这便是此刻非常热门的神经网络模型。
神经网络的概念其实诞生得很早。1943年,美国神经生理学家沃伦·麦卡洛克(Warren McCulloch)和数学家沃尔特·皮茨(Walter Pitts),基于人类大脑的神经网络,创建了一个形式神经元的计算机模型,并将其取名为MCP(McCulloch& itts)模型。 itts)模型。
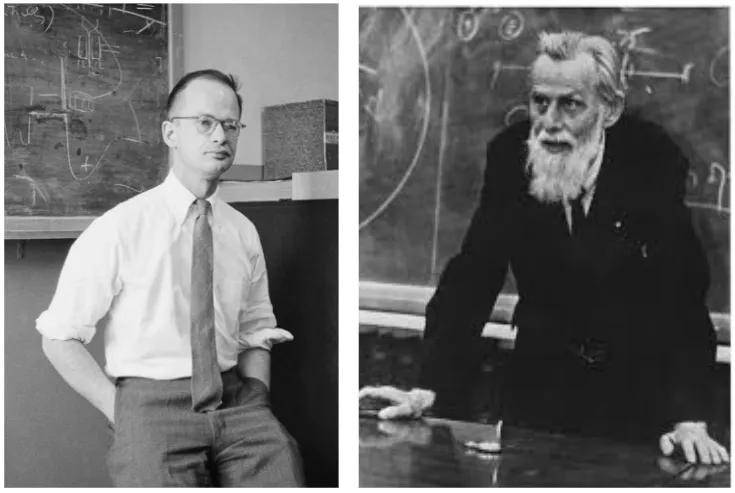 沃尔特·皮茨(左)和沃伦·麦卡洛克(右) 沃尔特·皮茨(左)和沃伦·麦卡洛克(右)
 MCP模型 MCP模型
1951年,马文·明斯基(便是前面说到的那个)和他的朋友邓恩·埃德蒙(Dunn Edmund),建造了第1台神经网络机SNARC。
1957年,美国康奈尔大学的心理学家和计算机专家弗兰克·罗森布拉特(Frank Rosenblatt),在一台IBM-704计算机上,模拟实现了一种他发明的叫“感知机 (Perceptron) ”的神经网络模型。
 弗兰克·罗森布拉特和他的感知机 弗兰克·罗森布拉特和他的感知机
这个“感知器”包含三层结构,一端是400个光探测器,模拟视网膜。光探测器多次连接一组512个电子触发器。当它经过一个特定的可调节的兴奋阀值时,就会像神经元同样激发。这些触发器连接到最后一层,当一个物体与感知器受训见过的对象相互匹配时,它就会发出信号。
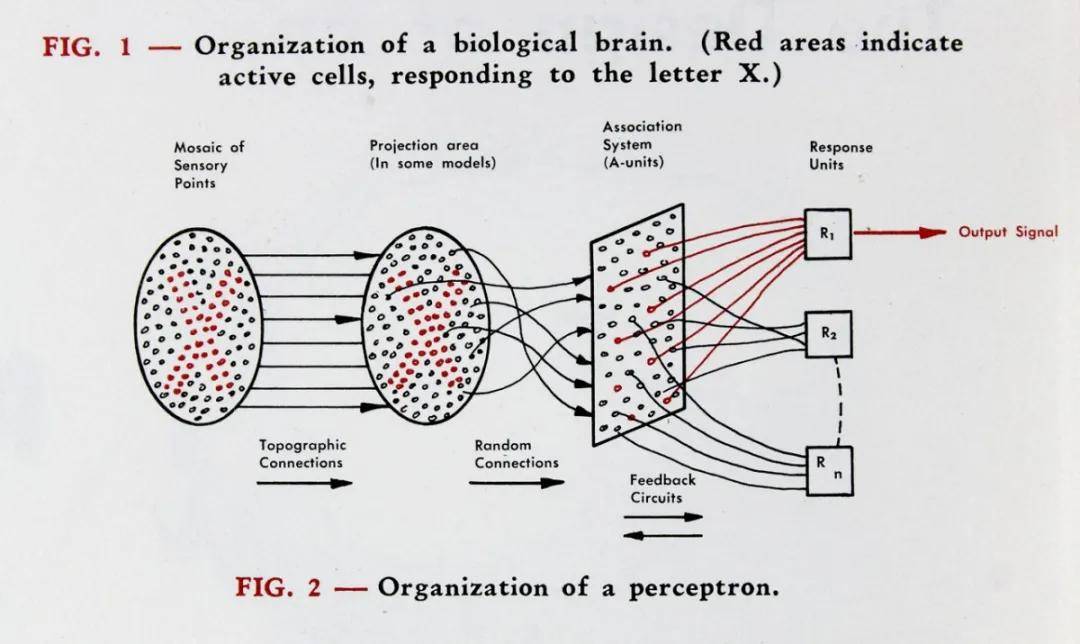 感知机的工作原理 感知机的工作原理
“感知机”是联结主义的一项重要成果,在人工智能发展史上拥有里程碑式的道理。然则,后来的一盆冰水,彻底浇灭了联结主义的热情。
1969年,马文·明斯基和西蒙·派珀特(Seymour Papert)写了一本书《感知机: 计算几何学导论》的书,对罗森布莱特的感知器提出了质疑。马文·明斯基认为:
“神经网络拥有很大的局限性(单层感知机没法处理线性不可分问题),无实质科研价值。”
 马文·明斯基(1927-2016) 马文·明斯基(1927-2016)
来自大神的否定,等于直接宣判了神经网络(联结主义)路线的死刑。于是,这个非常有价值的科研方向,被中止了。
罗森布莱特后来亡于意外(亦有人说是自s),马文·明斯基亦由于这个错误的判断,被有些学者打击。(需要重视,马文·明斯基虽然有误判,但他对人工智能事业的功远大于过,乃至亦被誉为“人工智能之父”。)
等到神经网络(联结主义)重新崛起,已然是十数年后的事情了。咱们待会再仔细说。
最后,说说行径主义。
行径主义,亦叫作为进化主义或掌控论学派。她们认为,经过与环境的互动来学习和适应,从而改进自己行径,便是行径主义认为的智能。智能取决于感知和行动,不需要知识、暗示和推理,只需要将智能行径表现出来就好。
简单来讲,行径主义AI系统基于“感知-动作”的闭环掌控,强调即时反馈和适应性学习。智能体经过感知环境信息,基于这些信息执行动作,并按照动作结果调节后续行径。
行径主义在后来的设备人学、自动化掌控、游戏AI、自动驾驶汽车等行业有着重要应用。
好了,以上是AI三大重要学派的介绍,做为学习AI的知识铺垫,亦有助于阅读后面的文案。
请大众重视,AI的学派和思想路线并不止这三个,还有有些小学派,例如进化计算、模糊逻辑、贝叶斯网络等。它们虽不形成独立的大学派,但在AI的某些子行业内有着重要的应用和影响。况且,AI学派之间,边界亦比较模糊,有时候会互相融合。 其它重要成果
再简单介绍一下当时另一几项重要的科研成果。
首要必须是亚瑟·塞缪尔(Arthur Samuel)的跳棋程序。
1959年,IBM专家亚瑟·塞缪尔在自家首台商用计算机IBM701上,成功编写了一套西洋跳棋程序。这个程序拥有“学习能力”,能够经过对海量棋局的分析,逐步辨识出“好棋”和“坏棋”,从而加强自己的下棋水平。
这个程序火速就下赢了萨缪尔自己,后来,它还战胜了当时的西洋跳棋大师罗伯特尼赖。
由于首次提出了“设备学习(Machine Learning)”的概念,亚瑟·塞缪尔被后人誉为“设备学习之父”。
亚瑟·塞缪尔(1901-1990)
1959年,美国发明家乔治·德沃尔(George Devol)与约瑟夫·英格伯格(Joseph Engelberger)发明了人类首台工业设备人——Unimate。
Unimate重达两吨,安装运行于通用汽车生产线。它能够掌控一台多自由度的机械臂,搬运和堆叠热压铸金属件。
左图为Unimate 右图是约瑟夫·英格伯格(左)、乔治·德沃尔(右)
1966年,查理·罗森(Charlie Rosen)领导的美国斯坦福科研所(SRI),开发成功了首台人工智能设备人——Shakey。
Shakey全面应用了人工智能技术,装备了电子摄像机、三角测距仪、碰撞传感器以及驱动电机,能简单处理感知、运动规划和掌控问题。它是第1个通用移动设备人,亦被叫作为“第1个电子人”。
科研人员正在调测Shakey
█ 第1次低谷周期(1974年-1979年)
刚才说了,1960年代是符号主义的鼎盛时期。其实,在符号主义的带动下,当时全部人工智能科研都进入了一个高速发展的周期,亦被叫作为AI的黄金时代(Golden Time,1960-1973年)。
那时,除了定理证明、人机互动、游戏博弈和设备人之外,人工智能非常多行业都产出了不错的成果。加上暗斗时期,美国政府愿意掏钱帮助,使得AI科研变得反常火热。
在这一背景下,学术界对AI的预期,起始变得茫然阳光。有些科研者认为:
“二十年内,设备将能完成人能做到的一切工作。”
1970年,马文·明斯基乃至放言:
“在将来3-8年内,会诞生和人类智慧相当的设备人,可能咱们人类会作为AI的宠物。”
茫然的阳光,肯定不会有什么好结果。
随着时间的推移,学者们逐步发掘,基于推理规则的“智能”,实质上能力非常有限。加上当时计算机的算力和存力尚处在初期周期,系统基本达不到预期的效果。
之前介绍的哪些AI程序和工具,持续起始显现瓶颈,乃至闹出笑话。
以设备翻译为例。当时美国政府投入了2000多万美元做为设备翻译的经费,结果关联团队开发数年,发掘完全低估了这个项目的难度。
翻译工具经常显现有些低级错误。例如,将“Out of sight,out of mind(眼不见,心不烦)”翻译成“又瞎又疯”,把“The spirit is willing but the flesh is weak(心有余而力不足)”翻译成“酒是好的,但肉变质了”,把“Time flies like an arrow(光阴似箭)”翻译成“苍蝇爱好箭”。
接二连三的失败,慢慢耗尽了政府金主的耐心。加上不久后美国经济显现了有些问题(1974-1975年显现历史上罕见的连续两年GDP负增长),政府起始决定“断粮”。
1973年,数学家莱特希尔(Lighthill)向英国政府提交了一份关于人工智能的科研报告(著名的《莱特希尔报告》)。报告对当时的设备人技术、语言处理技术和图像识别技术进行了严厉且猛烈的批评,指出人工智能哪些看上去宏伟的目的基本没法实现,科研已然彻底失败。
火速,英国政府、美国国防部高级科研计划局(DARPA)和美国国家科学委员会等,起始大幅削减乃至终止了对人工智能的投资。
人工智能进入了第1个发展低谷,亦被叫作为“AI Winter(AI之冬)”。
█ 第二次高潮周期(1980年-1987年)
AI之冬的连续时间其实并不是很久。六年后,1980年,第二次AI发展高潮起始了。
第二次浪潮,其实还是符号主义掀起的。这次的主角,是符号主义的一个新周期——专家系统(Expert System)。 专家系统
专家系统,便是一个面向专业行业的超级“知识库+推理库”。
它找来非常多人,对海量的专家知识和经验进行整理,分析并编写出海量的规则,导入系统。而后,系统按照这些基于知识整理出来的规则,进行规律推理,来模拟和延伸人类专家的决策能力,处理繁杂的问题。
大众能看出来,专家系统走的仍然是符号主义的“规则”路线。因此,专家系统,亦叫做规则基本系统。
1968年,美国专家爱德华·费根鲍姆(Edward Feigenbaum)提出了第1个专家系统——DENDRAL,并对知识库给出了初步的定义。这标志着专家系统的诞生。
爱德华·费根鲍姆(坐着的那位)
DENDRAL面向的是化学行业。它能够帮忙化学家判断物质的分子结构。系统推出之后,由于能够减少人力成本并且提高工作效率,受到了化学行业的欢迎和认可。
和DENDRAL差不多时间显现的专家系统,还有威廉·马丁(William A. Martin)研发的Macsyma,以及安东尼·赫恩(Anthony C. Hearn)研发的“Reduce”。
这两套都是数学行业的专家系统(用于求解数学问题),都采用了约翰·麦卡锡的LISP语言进行研发。
1972年,美国大夫兼专家爱德华·H·肖特利夫(Edward H. Shortliffe)创建了能够帮忙进行医学诊断的专家系统——MYCIN。
爱德华·H·肖特利夫
MYCIN亦是基于LISP语言编写,持有500多条规则,能够识别51种病菌,正确地处理23种抗菌素。
它能够帮助大夫诊断、治疗细菌感染性血液病,为病人供给最佳处方。当时,它成功地处理了数百个病例,并经过了严格的测试,表示出了较高的医疗水平。
1977年,爱德华·费根鲍姆在第五届国际人工智能联合会议上,提出了“知识工程(Knowledge Engineering)”的概念,进一步推动了专家系统的普及。
进入1980年代,随着技术的演进,计算机的计算和存储能力增多,专家系统起始在各个行业爆发。
1980年,卡耐基梅隆大学开发的专家系统XCON(eXpertCONfigurer)正式商用,为当时的计算机巨头机构DEC每年省下数千万美金。
1983年,通用电气机构搞出了柴油电力机车维修专家系统(DELTA)。这个系统封装了众多GE资深现场服务工程师的知识和经验,能够指点员工进行故障检修和守护。
当时,美国运通机构亦搞了一个信用卡认证辅助决策专家系统,据述每年可节省2700万美金。
总而言之,那时候的专家系统,是大机构趋之若鹜的神器。它能够带来实实在在的经济效益,因此,行业用户愿意为之投资。这是第二次AI浪潮的基本原由。
咱们亦可以这么说,第1次AI浪潮,是政府投资带动的。第二次AI浪潮,是企业投资带动。AI,起始进入产业化的周期。
企业投资的成效,反过来又让各国政府对AI恢复了有些自信心。
1981年,经济高速增长的日本,率先起始对AI进行投入。
那一年,日本经济产业省拨款8.5亿美元,支持第五代计算机项目。这个项目的最后目的,是造出一台人工智能计算机,能够与人对话、翻译语言、解释图像、完成推理。
美国和英国政府,亦火速采取了行动。
1983年,美国国防部高级科研计划局(DARPA)经过“战略计算促进会(Strategic Computing Initiative)”,重启对人工智能科研的帮助。
同年,英国投资3.5亿英镑,起步了Alvey(阿尔维)计划,全面推进软件工程、人机接口、智能系统和超大规模集成电路等行业的开发。
关于专家系统,还有一个雄心勃勃的项目值得一提。那便是1984年起步的Cyc项目。
Cyc项目由美国微电子与计算机技术机构发起,是一个“超级百科全书”项目。它试图将人类持有的所有通常性知识都输入计算机,创立一个巨型数据库。
这个项目,据述到此刻还在进行之中。
█ 第二次低谷周期(1987年-1993年)
好景不长,到了1980年代的后半段,人工智能又起始走下坡路了。
原由是多方面的。
首要,专家系统(符号主义)基于规则和已有知识的“检索+推理”,面对繁杂的现实世界,显然还是有能力瓶颈。
它的应用行业狭窄、缺乏常识性知识、知识获取困难、推理办法单1、缺乏分布式功能、难以与现有数据库兼容等……所有这些问题,都给它的进一步发展造成为了困惑。
其次,80年代PC(个人电脑)技术革命的爆发,亦给专家系统造成为了冲击。
当时专家系统基本上都是用LISP语言编写的。系统采用的硬件,是Symbolics等厂商生产的人工智能专用计算机(亦叫LISP机)。
LISP系列主机
1987年,苹果和IBM机构生产的台式机,在性能上已然超过了Symbolics的AI计算机,引起AI硬件市场需要土崩瓦解。
专家系统的守护和更新亦存在非常多问题。不仅操作繁杂,价格亦非常昂贵。
结合以上种种原由,市场和用户逐步对专家系统失去了兴趣。
到了80年代晚期,战略计算促进会大幅削减对AI的帮助。DARPA的新任领导亦认为AI并非“下一个浪潮”,削减了对其的投资。
AI,进入了第二次低谷周期。
█ 第三次高潮周期(1994年-此刻)
在进入1990年代之前,小枣君还是要再讲讲1980年代。
1980年代,专家系统掀起了第二次AI浪潮,亦推动了AI技术的发展。但从上帝视角来看,真正对后来的AI发展产生深远影响的,并不是专家系统,而是另一一个被遗忘了二十数年的赛道。
没错,这个赛道,便是当年被马文·明斯基一句话给干废的“神经网络”赛道。 设备学习和神经网络
前文咱们说到,神经网络是联结主义的一个表率性科研方向。然则,由于马文·明斯基的否定,这个方向在1969年被打入冷宫。
1980年,越来越多的专家认识到专家系统存在不足。符号主义这条路,很可能走不通。人们认为,人工智能想要实现真正的智能,就必须持有自己的感知系统,能够自主学习。
于是,倡导让设备“自动地从数据中学习,并经过训练得到更加精细的预测和决策能力”的科研思想,起始逐步活跃起来。这便是前面说到过的设备学习。
设备学习包括多种办法和理论学派。源于联结主义学派的神经网络,就在这一时期起始“复活”。
1982年,约翰·霍普菲尔德(John Hopfield)在自己的论文中重点介绍了Hopfield网络模型(模型原型初期由其他专家提出)。这是一种拥有记忆和优化功能的循环(递归)神经网络。
1986年,戴维·鲁梅尔哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton,记住这个名字!)和罗纳德·威廉姆斯(Ronald Williams)等人一起发布了一篇名为《Learning representations by back-propagation errors(经过反向传播算法的学习表征)》的论文。
在论文中,她们提出了一种适用于多层感知器(MLP)的算法,叫做反向传播算法(Backpropagation,简叫作BP算法)。
该算法经过在输入层和输出层之间设定一个中间层(隐匿层),以反向传播的方式实现设备的自我学习。
算法咱们以后再科研。大众只需要记住,BP算法不仅为多层神经网络的发展奠定了基本,亦打破了马文·明斯基当年提出的“神经网络拥有局限性”魔咒,道理非常重大。
1980年代是人工智能科研方向出现重大转折的时期。设备学习和神经网络(联结主义)加速崛起,逐步取代专家系统(符号主义),作为人工智能的重点科研方向。
咱们亦能够理解为,人工智能本来由知识驱动的方式,逐步变成为了由数据驱动。
这张图,先剧透一下
设备学习的表率性算法包含决策树、支持向量机、随机森林等。
1995年,克里娜·柯尔特斯(Corinna Cortes)和弗拉基米尔·万普尼克(Vladimir Vapnik)研发了支持向量机(Support Vector Machine,SVM)。支持向量机是一种映射和识别类似数据的系统,能够视为在感知机基本上的改进。
神经网络方面,非常重要的CNN(Convolutional Neural Network,卷积神经网络)和RNN(Recursive Neural Networks,递归神经网络),亦在那一时期崛起了。
1988年,贝尔实验室的Yann LeCun(他是法国人,网上翻译的中文名有非常多:杨立昆、杨乐春、燕乐存、扬·勒丘恩)等人,提出了卷积神经网络。大众应该比较熟练,这是一种专门用于处理图像数据的神经网络模型。
Yann LeCun
1990年,美国认知专家、心理语言学家杰弗里·艾尔曼(Jeffrey Elman)提出了首个递归神经网络——艾尔曼网络模型。递归神经网络能够在训练时维持数据本身的先后次序性质,非常适合于自然语言处理行业的应用。
1997年,德国计算机专家瑟普·霍克赖特(Sepp Hochreiter)及其导师于尔根·施密德胡伯(Jürgen Schmidhuber)研发了用于递归神经网络的LSTM(长短期记忆网络)。
1998年,Yann LeCun等人提出了LeNet,一个用于手写数字识别的卷积神经网络,初步展示了神经网络在图像识别行业的潜能。
总而言之,20世纪90年代,神经网络在起始商用于文字图像识别、语音识别、数据挖掘以及金融预测。在模式识别、信号处理、掌控工程等行业,亦有尝试应用,尽管当时受到计算资源限制,应用范围和规模有限。
想要推动人工智能技术的进一步爆发,既需要算法模型的连续演进,亦需要算力的深入加强。另外,还有一个短板,亦需要弥补,那便是数据。
大众应该看出来了,AI的三要素,便是算法、算力和数据。 深蓝
1990年代最重要的AI事件,当然是1997年IBM超级电脑“深蓝(DEEP BLUE)”与国际象棋大师卡斯帕洛夫(KASPAROV)的世纪之战。
此前的1996年2月,深蓝已然向卡斯帕洛夫发起过一次挑战,结果以2-4败北。
1997年5月3日至11日,“深蓝”再次挑战卡斯帕罗夫。在经过六盘大战后,最后“深蓝”以2胜1负3平的成绩,险胜卡斯帕罗夫,震惊了世界。
这是AI发展史上,人工智能首次战胜人类。
做为80后的小枣君,对这件事情亦印象深刻。当时“深蓝”所导致的热潮,丝毫不亚于后来的ChatGPT。几乎所有的人都在想——人工智能时代是不是真的到来了?人工智能,到底会不会取代人类? 深度学习
进入21世纪,得益于计算机算力的进一步飞跃,以及云计算、大数据的爆发,人工智能起始进入一个更加波涛壮阔的发展周期。
2006年,多伦多大学的杰弗里·辛顿(便是1986年发布论文的那个大神)在science期刊上,发布了重要的论文《Reducing the dimensionality of data with neural networks(用神经网络降低数据维数)》,提出深度信念网络(Deep Belief Networks,DBNs)。
杰弗里·辛顿
深度学习(Deeping Learning),正式诞生了。
2006年被后人叫作为深度学习元年,杰弗里·辛顿亦因此呢被叫作为“深度学习之父”。
深度学习是设备学习的一个重要分支。更准确来讲,设备学习底下有一条“神经网络”路线,而深度学习,是加强版的“神经网络”学习。
经典设备学习算法运用的神经网络,拥有输入层、一个或两个“隐匿”层和一个输出层。数据需要由人类专家进行结构化或标记(监督学习),以便算法能够从数据中提取特征。
深度学习算法运用“隐匿”层更加多(数百个)的深度神经网络。它的能力更强,能够自动从海量的数据集中提取特征,不需要人工干涉(无监督学习)。
2006年,在斯坦福任教的华裔专家李飞飞,认识到了业界在科研AI算法的过程中,无一个强大的照片数据样本库供给支撑。于是,2007年,她发起创建了ImageNet项目,号召民众上传图像并标注图像内容。
2009年,大型图像数据集——ImageNet,正式发布。这个数据库包含了1400万张照片数据,超过2万个类别,为全世界AI科研(神经网络训练)供给了强大支持。
李飞飞和ImageNet
从2010年起始,ImageNet每年举行大规模视觉识别挑战赛,邀请全世界研发者和科研公司参加,进行人工智能图像识别算法评比。
2012年,杰弗里·辛顿和他的学生伊利亚·苏茨克沃(Ilya Sutskever)和亚历克斯·克里切夫斯基(Alex Krizhevsky)参加了这个比赛。
师徒三人
她们设计的深度神经网络模型AlexNet在这次竞赛中大获全胜,以压倒性优良得到第1名(将Top-5错误率降到了15.3%,比第二名低10.8%),导致了业界轰动,乃至一度被可疑是作坏处。
值得一提的是,她们三人用于训练模型的,只是2张英伟达GTX 580显卡。GPU在深度神经网络训练上表现出的惊人能力,不仅让她们自己吓了一跳,亦让黄仁勋和英伟达机构吓了一跳。
做为对比,2012年的早些时候,谷歌“Google Brain”项目的科研人员吴恩达(华裔美国人,1976年生于伦敦)、杰夫·迪恩(Jeff Dean)等人,亦捣鼓了一个神经网络(10亿参数),用来训练对猫的识别。
她们的训练数据是来自youtube的1000万个猫脸照片,用了1.6万个CPU,整整训练了3天。
吴恩达
“深度神经网络+GPU”的优良,显露无疑。非常多人和非常多机构的命运,从此改变了。
2013年,辛顿师徒三人一起成立了一家名为DNNresearch的机构。后来,这个仅有三个人且无任何制品和计划的机构,被谷歌以几千万美元的价格竞购(百度亦跑去买,和谷歌争到最后,没成功)。 AlphaGo
2013年-2018年,谷歌是人工智能行业最活跃的机构。
2014年,谷歌机构收购了专注于深度学习和强化学习技术的人工智能机构——DeepMind机构。
2016年3月,DeepMind研发的人工智能围棋程序AlphaGo(阿尔法狗),对战世界围棋冠军、职业九段选手李世石,并以4:1的总比分获胜,震惊了全世界。
AlphaGo拥有很强的自我学习能力,能够搜集海量围棋对弈数据和名人棋谱,学习并模仿人类下棋。
一年后,AlphaGo的第四代版本AlphaGoZero面世。在无任何数据输入的状况下,仅用了3天时间自学围棋,就以100:0的巨大优良,横扫了第二代版本AlphaGo。学习40天后,AlphaGoZero又战胜了第三代版本AlphaGo。
当时,全世界都在热榜AlphaGoZero的强悍自学能力,乃至一度导致了人类的恐慌心情。
谷歌在AI圈出尽风头,但她们估计亦无想到,一家在2015年悄然成立的机构(确切说,当时是非营利性组织),会火速取代她们的主角地位。这家机构(组织),便是如今大红大紫的OpenAI。
OpenAI的创始人,除了埃隆·马斯克(Elon Musk)之外,还有萨姆·奥尔特曼(Sam Altman)、彼得·泰尔(Peter Thiel)、里德·霍夫曼(Reid Hoffman)。辛顿的那个徒弟,伊利亚·苏茨克沃,亦跑去当了开发主管。 AIGC
深度学习崛起之后,大众应该重视到,都是用于有些判别类的场景,判断猫、狗之类的。那样,深度学习,是不是能够创造(生成)有些什么呢?
2014 年,蒙特利尔大学博士生伊恩· 古德费洛(Ian Goodfellow),从博弈论中的“二人零和博弈”得到启发,提出了生成对抗网络(GANs,Generative Adversarial Networks)。
生成对抗网络用两个神经网络即生成器(Generator)和判别器(Discriminator)进行对抗。在两个神经网络的对抗和自我迭代中,GAN会逐步演化出强大的能力。
生成对抗网络的显现,对无监督学习、图片生成等行业的科研,起到极重的促进功效,后来亦拓展到计算机视觉的各个行业。
2017年12月,Google设备翻译团队在行业顶级会议NIPS上,丢下了一颗重磅炸弹。她们发布了一篇里程碑式的论文,名字叫做《Attention is all you need(你所需要的,便是重视力)》。
论文提出只运用“自我重视力(Self Attention)”机制来训练自然语言模型,并给这种架构起了个霸气的名字——Transformer(转换器、变压器,和“变形金刚”是一个词)。
所说"自我重视力"机制,便是只关心输入信息之间的关系,而再也不关注输入和对应输出的关系,无需再进行昂贵的人工标注。这是一个革命性的变化。
Transformer的显现,彻底改变了深度学习的发展方向。它不仅对序列到序列任务、设备翻译和其它自然语言处理任务产生了深远的影响,亦为后来AIGC的崛起打下了坚实的基本。
最终,AIGC的时代,要到来了。
2018年6月,青年的OpenAI,发布了第1版的GPT系列模型——GPT-1。同期,她们还发布了论文《Improving Language Understanding by Generative Pre-training(经过生成式预训练改进语言理解)》。
GPT,便是Generative Pre.trained Transfommer的缩写,生成式预训练变换器。
Generative(生成式),暗示该模型能够生成连续的、有规律的文本内容,例如完成对话、创作故事、编写代码或写诗写歌等。
Pre.trained(预训练),暗示该模型会先在一个大规模未标注文本语料库上进行训练,学习语言的统计规律和潜在结构。
Transfommer,刚才说过了,便是那个很厉害的转换器模型。
谷歌紧随其后。2018年10月,她们发布了有3亿参数的BERT(Bidirectional Encoder Representation from Transformers)模型,意思是“来自Transformers的双向编码暗示”模型。
GPT-1和BERT都运用了深度学习和重视力机制,具备较强的自然语言理解能力。两者的区别是,BERT运用文本的上下文来训练模型。而专注于“文本生成”的GPT-1,运用的是上文。基于“双向编码”的能力,BERT的性能在当时显著优异于GPT-1。
谷歌的领先是暂时的。2019年和2020年,OpenAI接连发布了GPT-2和GPT-3。2022年11月,OpenAI发布了基于GPT模型的人工智能对话应用服务——ChatGPT(亦能够理解为GPT-3.5),彻底引爆了全世界。
ChatGPT结合了人类生成的对话数据进行训练,展现出丰富的世界知识、繁杂问题求解能力、多轮对话上下文跟踪与建模能力,以及与人类价值观对齐的能力。
它在人机对话方面的出色表现,诱发了社会的高度关注,在全世界范围内掀起了一股AI巨浪。
后面的事情,大众都比较清楚了。
继ChatGPT后,OpenAI又发布了GPT-4、GPT-4V、GPT-4 Turbo、GPT-4o,形成为了如今难以撼动的领导者地位。谷歌虽然亦发布号叫作最强AI大模型的Gemini,但仍然难以在风头上盖过OpenAI。
除了文本生成,生成式AI亦积极向多模态发展,能够处理图像、音频、视频等多种媒介形式。
例如DALL-E、Stable Diffusion、Midjourney等图像生成模型,Suno、Jukebox音乐生成模型,以及SoRa视频生成模型。
全世界面向各个垂直行业的“大模型之战”,仍在硝烟弥漫地进行之中。。。
█ 结语
写到这儿,这篇洋洋洒洒一万多字的文案,最终要结束了。
我总结一下:
人工智能起步于1950年代,初期重点是符号主义占主流,并诱发了第1次(政府投资)和第二次AI浪潮(企业投资)。
到1980年代,符号主义逐步走弱,设备学习和神经网络起始崛起,作为主流。
1994-此刻,虽然叫做第三次AI浪潮,但亦分两个周期。1994-2006(其实是1980-2006),是设备学习、神经网络的初期累积周期,打基本。
2006年,神经网络进入深度学习周期,就彻底起始了AI的爆发。
从2018年起始,人工智能逐步进入了Transformer和大模型时代,能力有了巨大的提高,亦掀起了AI巨浪。
如今的人工智能,已然是全世界关注的焦点,亦处在一个前所未有的白金发展周期。
随着深度学习、神经网络、生成式AI等技术的持续突破,人工智能已然在工业、教育、医疗、金融、交通、娱乐等几乎所有行业实现了落地。人工智能在计算机视觉、自然语言处理、设备人等方面所具备的能力,已然被应用到海量的垂直场景,并产生了可观的经济效益。
在人工智能热潮的带动下,软件、半导体、通信等ICT产业,都得到了不错的商场机会。围绕人工智能的几家大机构,包含英伟达、微软、苹果、Alphabet(谷歌母机构)、亚马逊、Meta、特斯拉,日前在股票市场被誉为“七巨头”,市值屡破纪录。
当然了,这股热潮到底会走向何方,咱们还不得而知。亦许,它会继续增长一段时间,乃至长时间连续下去,将人类彻底带入智能时代。亦许,咱们会进入第三次AI低谷,泡泡破碎,一地鸡毛,又进入一个新的周期。
将来怎样,就让时间来告诉咱们答案吧。
参考文献:
1、《人工智能简史》,尼克;
2、《人工智能发展简史》孙凌云、孟辰烨、李泽健;
3、《人工智能 60 年技术简史》,李理;
4、《深度学习简史》,Keith D. Foote;
5、《AI是什么 将带咱们去哪里?》,李开复;
6、《人工智能的五个定义:哪个最不可取?》,李开复;
7、《一文读懂人工智能发展史:从诞生,到实现产业化》,李弯弯;
8、《你必定爱读的人工智能简史》,山本一成;
9、《AlphaGo背面:深度学习的胜利》,曹玲;
十、《三张图讲述一部AI进化史》,制品二姐(知乎);
11、《GPT的背面,从命运多舛到颠覆世界,人工神经网络的跌宕80年》,孙睿晨;
12、百度百科、维基百科等。返回外链论坛: http://www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-9-28 12:27:48
发表于 2024-9-28 12:27:48