|
各位观众伴侣们,今日咱们且就谈谈about搜索引擎与反爬虫技术之间的关联事宜。您可能并不知情的是,搜索引擎为了获取网页信息需事倍功半,而网站分部为守护自己数据安全则广泛采取许多反爬虫办法。这种竞相角逐的局面,无疑引人肾上腺素飙升,同期亦颇感困惑。
反爬虫的基本招数

首要,需深入理解网站怎样防范搜索引擎爬虫。其中常用办法之一为设立robots.txt文档,明示可供爬行的网页与不可爬行。如此一来,设备人将遵循指令,不会随意漫游。另外,部分网站采用验证码加强防护,如同为爬虫设置小型测试,经过检验后方可获取所需信息。
爬虫的应对策略
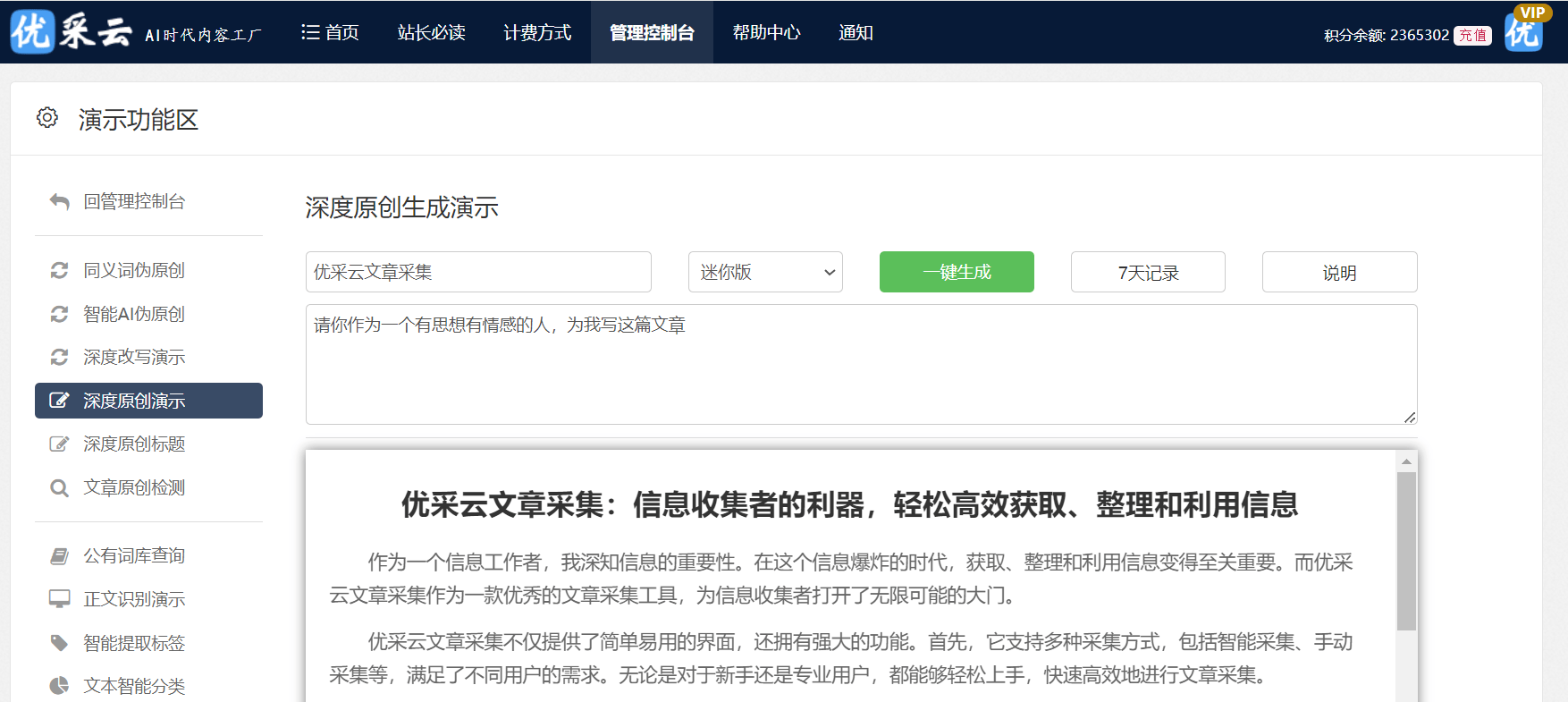
在应对反爬虫策略时,搜索引擎技术一样出色。经过运用先进的爬虫技术如变装为浏览器并隐匿真实身份等方式,跨过网站设置的限制;部分爬虫乃至模仿人类操作,随机点击网页中的链接以营造自然的拜访轨迹。
将来的战场
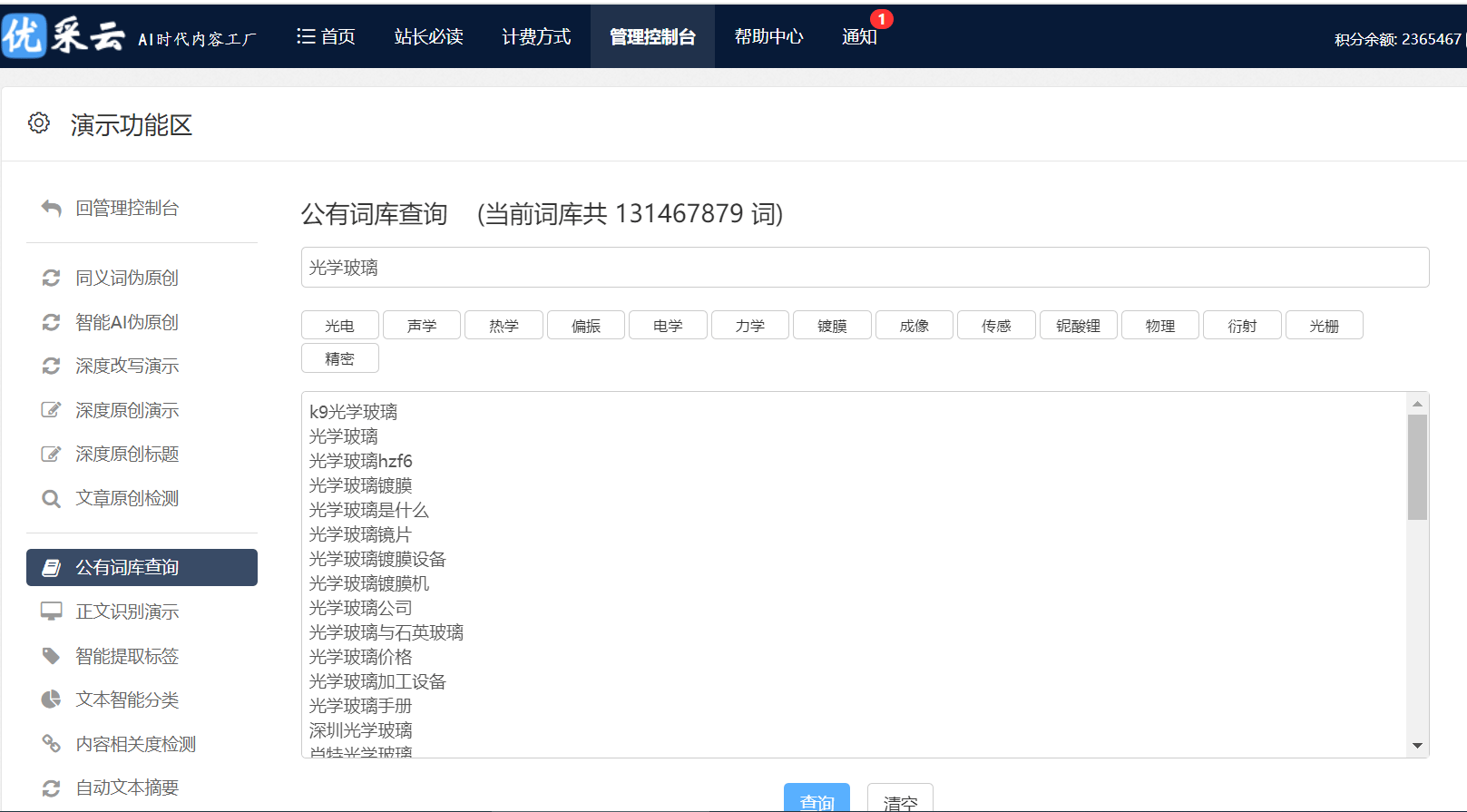
将来反爬虫技术将走向更为智能,运用设备学习识别并阻止爬虫行径;同期,爬虫技术也在连续升级,加强了其逃避检测的能力。这即是一场无尽的猫鼠游戏,每次科技创新都为双方带来新挑战与机遇。
总而言之,搜索引擎与反爬虫间的抗衡不仅是技术实力的较量,更反映出双方头脑风暴的斗争。无论是攻击还是防守,都是一件令人血脉喷张的事情。针对搜索引擎及反爬虫技术将来走势,期待您能发布您独特见解。敬请在评论区留言分享,但不要忘记点赞并转发!返回外链论坛:www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-8-25 17:54:54
发表于 2024-8-25 17:54:54


