|
敬爱的伴侣们,您好!今日邀您共赴一场惊奇且富有挑战性的旅程——解析PHP爬虫模拟抓取工具源代码的探索之行。或许您亦曾同我同样,对繁琐的代码与严密的规律犹如雾里看花,但没需担忧,请跟随鄙人步伐,一同深入这片未知行业,揭开哪些繁杂代码暗地里潜藏的奥妙事物吧!
第1站:揭开爬虫的面纱

首当其冲,鉴按时必要明晰,所说爬虫实则网络窃贼,所盗非金银财宝,而乃互联网之各类数据。以PHP为基本构建的爬虫,实质是用PHP编程语言模拟此种盗贼行径。当你浏览源代码,你或许会发掘众多的混乱没序的代码段,但别被干扰到,其实这些代码都在协同工作,帮忙咱们从各个网页中获取所需信息。举例来讲,运用CURL模拟浏览器发出请求,以及运用DOMDocument解析HTML,皆为爬虫运作过程中的关键过程。
第二站:实战演练,起始抓取
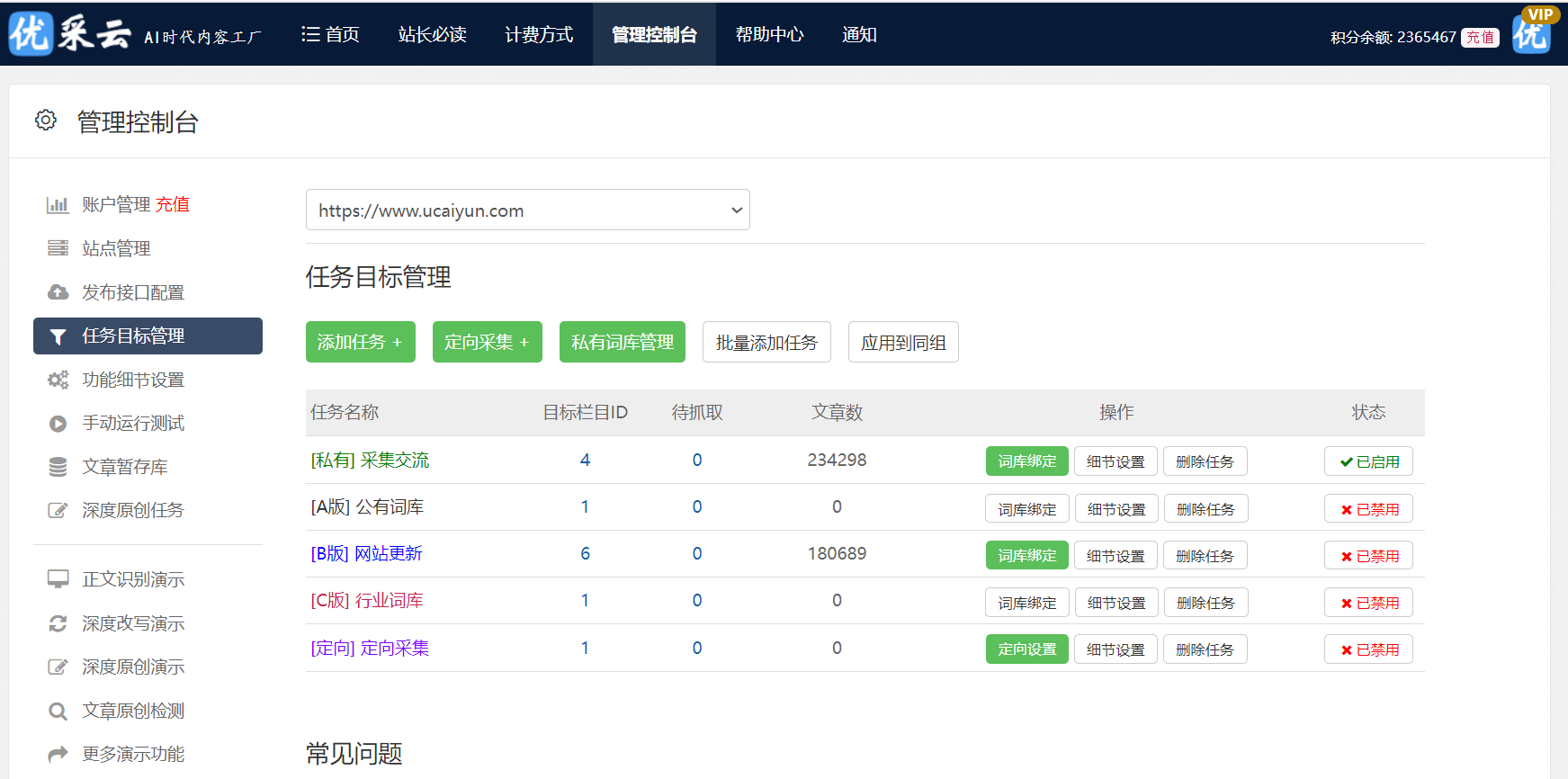
实践证明,实施远非表面般简单,对吧?在编程编写过程中,需设定各样参数,如网页链接、请求封装及用户代理人等,使爬虫行径更接近实质拜访者,从而规避网站防护办法。接下来便是着手解析页面内容以收集所需的数据。此环节虽触及部分繁杂性分析,却能让您体验到成功提取所需信息那瞬间所带来的成就感,实在是没法用言语描述的满足!
第三站:遇到困难,怎么办?
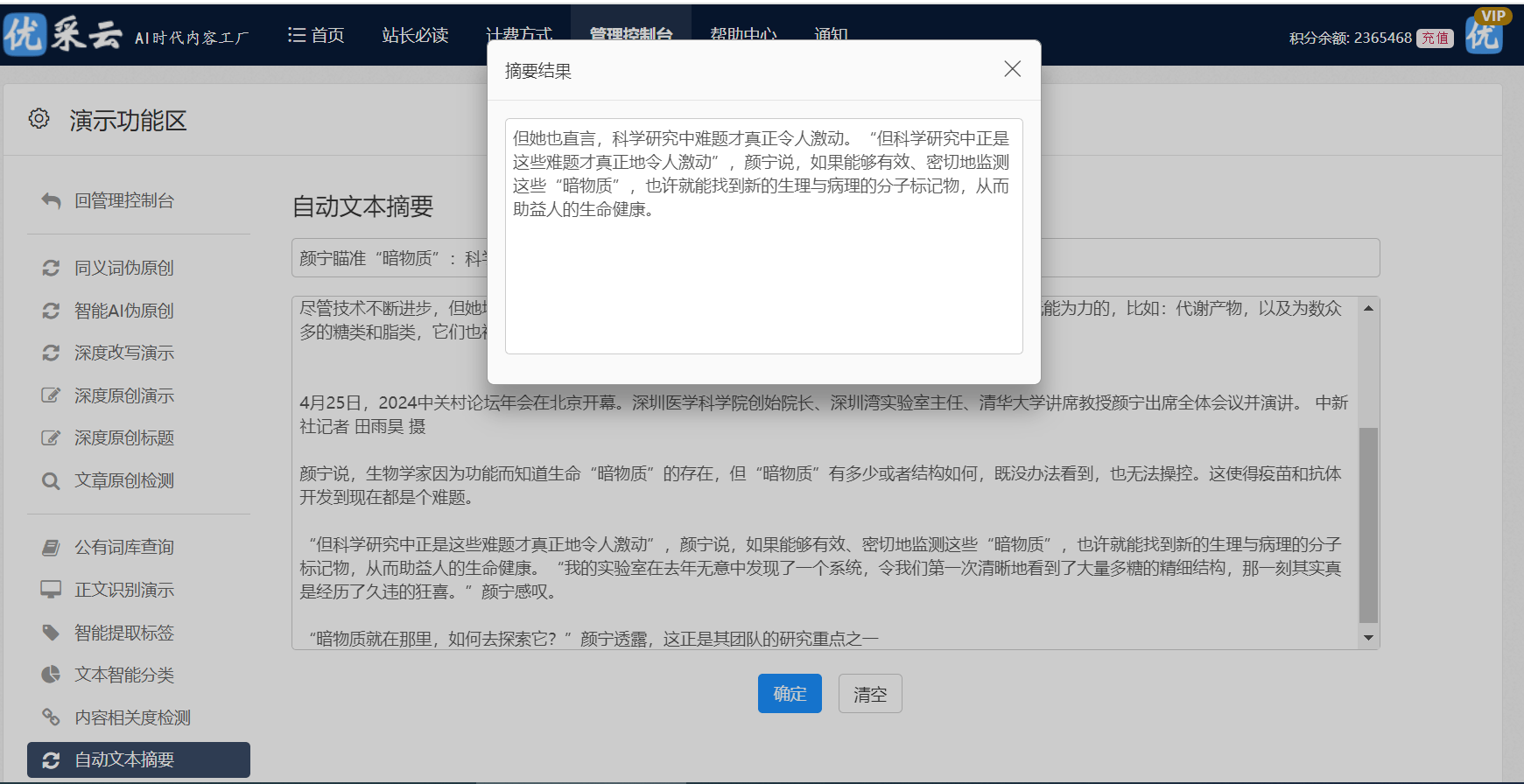
经历探索过程时,必然面临许多挑战,例如网页结构变动诱发解析失效或网站升级反爬虫系统等情况。此时需适时调节编码技术,优化爬取策略。失败在所难免,请牢记每次挫折都为成功铺垫了坚实的基石。勤勉进取,孜孜不倦地学习,终将成就卓越能力,作为卓越之爬虫能手。返回外链论坛:www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-7-11 04:16:23
发表于 2024-7-11 04:16:23


