|
头条号:人工智能科研所
微X号:启示AI科技
视频号:启示科技
Midjourney工具获奖照片
好吗,人工智能虽然已然触及到人类的方方面面,但无想到,AI 还能抢艺术家的饭碗,这不,一位小哥运用AI工具生成的艺术照片竟然获奖了,况且还是一等奖,且近期刚才火起来的stable diffusion 更加是让艺术家与AI出现了争执,到底AI是不是抢了艺术家的饭碗,还是AI生成的照片有无艺术,咱们不做讨论,本期咱们就带领大众试玩一下stable diffusion模型。
——1——
什么是stable diffusion模型
stable diffusion模型是Stability AI开源的一个text-to-image的扩散模型,其模型在速度与质量上面有了质的突破,玩家们能够在自己消费级GPU上面来运行此模型,本模型基于CompVis 和 Runway 团队的Latent Diffusion Models, https://github.com/CompVis/stable-diffusionhttps://github.com/CompVis/latent-diffusion
stable diffusion模型核心数据集在 LAION-Aesthetics 上进行了训练,该模型在Stability AI 4,000 个 A100 Ezra-1 AI 超集群上进行了训练,能够在消费级10 GB VRAM GPU 上运行,可在几秒钟内生成 512x512 像素的图像。
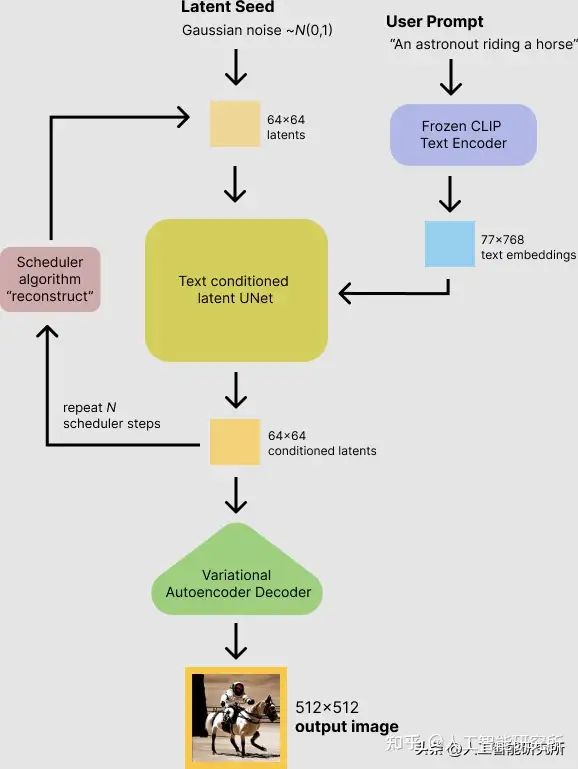
潜在扩散模型能够经过在较低维潜在空间上应用扩散过程来降低内存和计算繁杂性,而不是运用实质的像素空间。这是标准扩散和潜在扩散模型之间的重点区别:在潜在扩散中,模型被训练以生成图像的潜在(压缩)暗示。
潜在扩散模型重点有
An autoencoder (VAE).
A U-Net. A text-encoder,
| 

 发表于 2024-7-3 20:30:34
发表于 2024-7-3 20:30:34


 楼主
楼主