|
今天为大众整理了23个Python爬虫项目。整理的原由是,爬虫入门简单快速,亦非常适合新入门的小伙伴培养自信心,所有链接指向GitHub,微X不可直接打开,老规矩,能够用电脑打开。
1. WechatSogou – 微X公众号爬虫
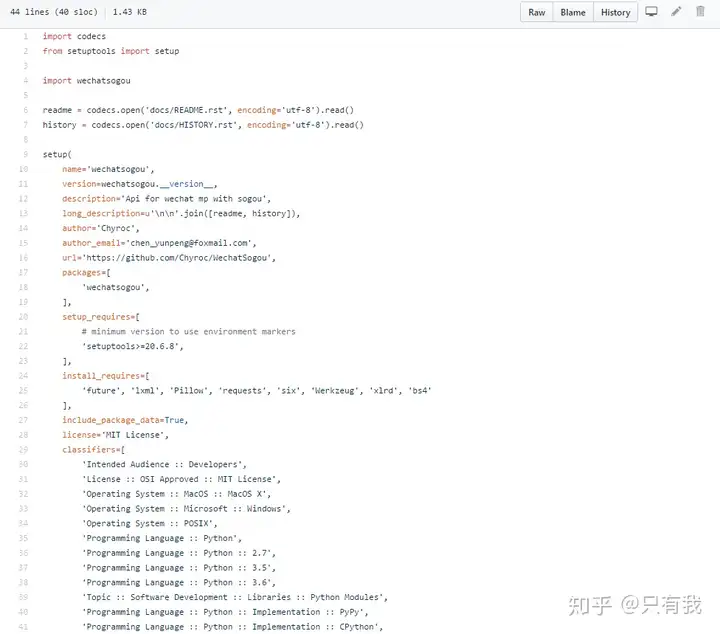
基于搜狗微X搜索的微X公众号爬虫接口,能够扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号详细信息字典。
部分代码截图:
2. DouBanSpider – 豆瓣读书爬虫
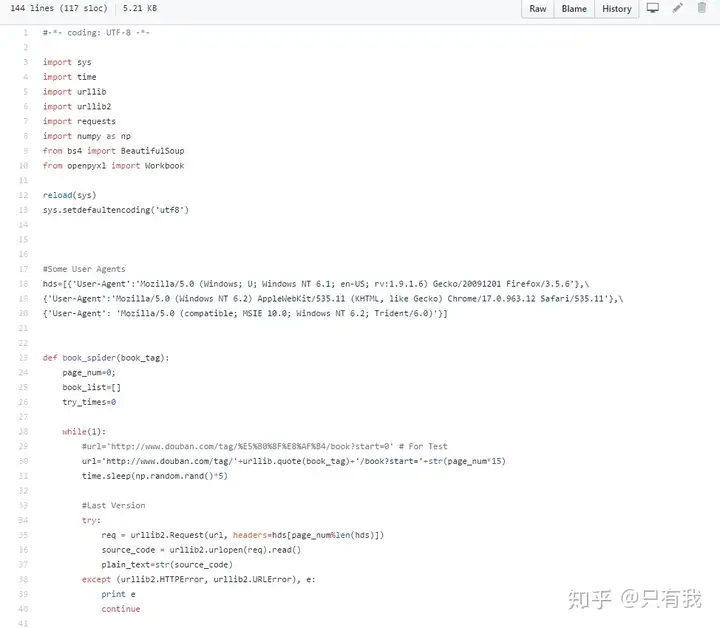
能够爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大众筛选搜罗,例如筛选评估人数>1000的高分书籍;可依据区别的主题存储到Excel区别的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行径,避免爬虫被封。
部分代码截图:
3. zhihu_spider – 知乎爬虫
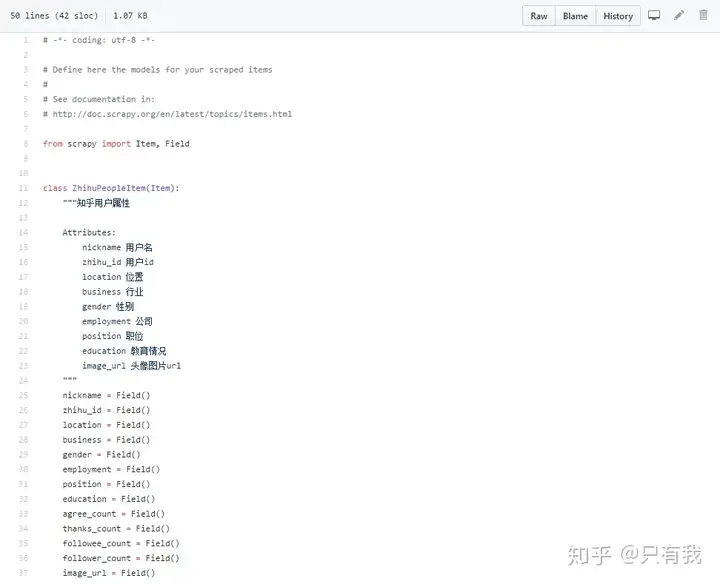
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架运用scrapy,数据存储运用mongo
部分代码截图:
4. bilibili-user – Bilibili用户爬虫
总数据数:20119918,抓取字段:用户id,昵叫作,性别,头像,等级,经验值,粉丝数,生日,位置,注册时间,签名,等级与经验值等。抓取之后生成B站用户数据报告。
部分代码截图:
| 

 发表于 2024-7-2 03:30:52
发表于 2024-7-2 03:30:52