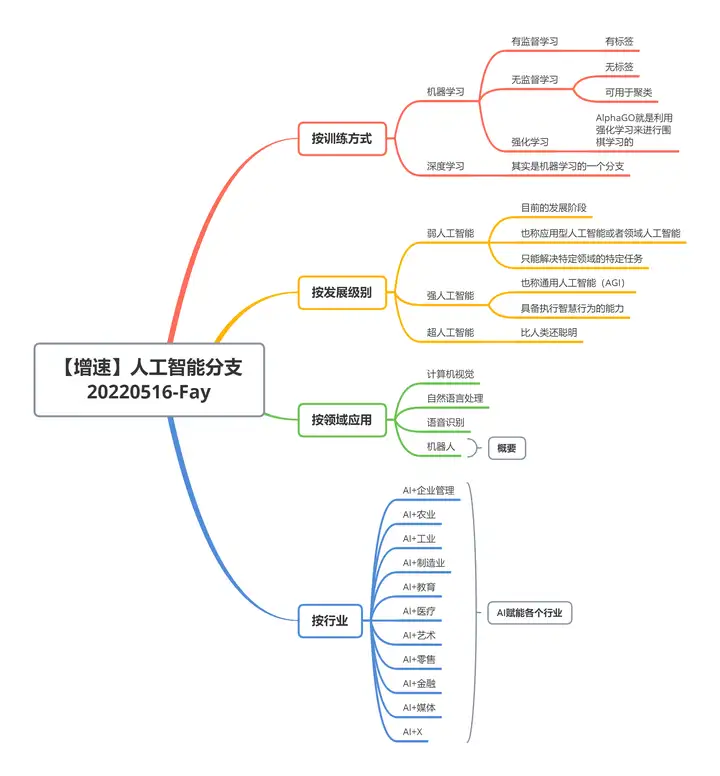
人工智能的归类
其实说到人工智能,大部分小白可能会想到人工智能便是很酷的与人类没异的设备人,如像《底特律:作为人类》游戏中所打造的将来世界。与真人没异的设备人,持有了选取的权利,情感以及认识,在为人类将来发展命运做着最后的抉择。
但……醒醒!
此刻还是2022年
人工智能还是处在初级发展周期
当人工智能拥有和人类没异的外观、感知能力、思想的时候,那时人工智能发展的高级周期了,亦叫做强人工智能或超人工智能。
日前人工智能的发展还只是初级周期。
因此呢,日前狭义上人工智能专业以及应用,叫做设备学习。
至于大众很关心讨论非常多的深度学习、神经网络,其实是设备学习的一个小分支,但因为它的效果过于强劲,实在是太火了,因此日前做为人工智能的一个蓬勃发展的分支经常拿来讨论。
针对人工智能的归类问题,我画了一个图总结了一下。
当前设备学习的重点归类能够分为有监督学习,没监督学习以及强化学习。
有监督学习和没监督学习,其中最大的区别便是是不是有标签,这个标签能够是人工标注的,亦能够使设备辅助标注的,亦便是能否有一个确定的标准答案让设备晓得,归类或是预测是不是为正确的。
其中有监督学习,能够再分为归类以及回归问题归类问题重点处理的便是,归类问题,重点处理的便是有些有标签的问题,能够针对有些种类进行一个归类,例如说猫狗归类以及区别品种的花进行归类。而回归问题其实便是进行一个预测,他并不是将目的任务目的任务分为,可数的、有穷尽的类别,不连续的,而是进行一个结果的预测,例如说2000和2000.1,之间的差别就不大,而归类问题,将目的识别为猫和狗的差别就会非常大。
其中没监督学习的重点任务是聚类。咱们事先并不晓得有些东西的标签,咱们亦不晓得有那些类别,设备按照这些目的的类似度来进行一个聚类,例如说能够在看音乐平台上都有哪类用户,或者社交平台上用户的画像。
强化学习是当今非常热门的一个科研方向,由于强化学习的本质便是基于现实在环境中得到反馈,从而持续改善学习状况,这其实就和咱们人类学习上面有非常大的类似度,咱们亦是经过接受外界的反馈来得到做对了或做错的反馈,来一次得到奖励或处罚,从而进一步强化自己正确的行径或改正自己错误的行为。像AlphaGo下围棋,还有自动驾驶技术,其实就运用了强化学习的办法。
Transformer网络(待填坑)
举个栗子,例如这个网络
通用人工智能最新突破:一个模型、一套权重通吃600+视觉文本和决策任务,DeepMind两年科研一朝公开
用业内的话说便是 “transformer is all you need”,亦是在玩梗了,由于transf
| 

 发表于 2024-7-1 07:08:23
发表于 2024-7-1 07:08:23