|
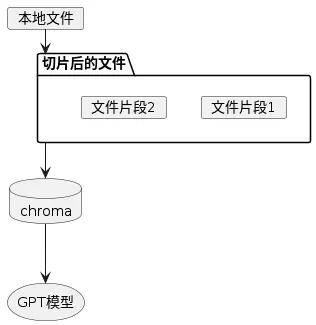
本文将基于 LangChain 实现一个 mini 的实战案例。这次实战重点完成的任务,便是设计一个测试答疑助手,这个测试答疑助手的重点功能为基于本地的文档和数据,回答给出的自然语言问题,例如有些数据的统计,查询、组合。
示例运用数据 测试用例文档设计文档需求文档实践演练
实战设计思路
安装依赖
安装依赖 chromadb,chromadb是一个简单快捷的向量数据库,为了减少对embedding模型的请求次数,设置数据保留的理学位置,这般多次运行代码亦不会重复请求模型转换向量:
pip install chromadb embedding:相当于一个“桥梁” —— 翻译:把照片,文字,视频以及音频所有转换为数字,并且包括了数据的信息,使得大模型都能”懂“,能利用这些数字去做训练和推理。向量:向量本身是一组数字,然则在几何上,向量的各个数字组成为了多维的数组空间,向量的每一个维度表率该空间的·一个区别的特征或属性。向量数据库:专门用于存储和管理向量数据的数据库,能对向量数据进行有效的操作。代码实现 经过环境变量设置API Token,以及关联依赖的导入:# 有些LangChain的依赖导入
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain.vectorstores import Chroma
# 加载openai 的 API Tokenfrom utils.data_load import get_auth
# 经过环境变量设置API Token,由于代码中的部分模型调用实例没法直接传递参数,必须经过环境变量设置的方式将token传递给自动构建的OpenAI请求
import os
os.environ[OPENAI_API_KEY] = open_ai_token
os.environ[OPENAI_API_BASE] = open_ai_url
2.处理源文档,将其切片处理:
# 定义一个函数,用于加载本地文件中的文本
def load_text_from_file(path: str) -> str:
return open(path, encoding=utf-8).read()
# 按照测试用例文档中的结构,定义一个MarkdownHeaderTextSplitter实例,用于将markdown文档切分为文本片段,方便后续embedding处理和向量数据库的构建
testcase_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=[("##", "模块名叫作"), ("###", "用例名叫作")])
docs = testcase_splitter.split_text(load_text_from_file(path="docs/测试用例.md"))
# 一样处理设计文档,由于设计文档中的结构与测试用例文档不一致,因此要新定义一个MarkdownHeaderTextSplitter实例
design_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=[("##", "功能名叫作"), ("###", "模块名叫作")])
docs += design_splitter.split_text(load_text_from_file(path="docs/设计文档.md"))
# 同理,处理需求文档
prd_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=[("###", "功能名叫作")])
docs += prd_splitter.split_text(load_text_from_file(path="docs/需求文档.md"))
# 将切分后的文本片段输出,能够查看切分结果,和里面附带的数据信息
for doc in docs:
print(doc)
3.倘若数据存在,则加载运用,倘若不存在,则写入:
persist_directory = chroma
# 读取数据
if os.path.isdir(persist_directory):
vectordb = Chroma(persist_directory=persist_directory, embedding_function=OpenAIEmbeddings())
else:
# 将切分后的数据,经过OpenAIEmbeddings实例,转换为向量数据,
# 并保留到向量数据库中,持久化到本地指定目录下
vectordb = Chroma.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
persist_directory=persist_directory
4.将向量数据库中检索到的文本片段以及提示词组作为 prompt,向大模型获取返回信息:
# 设定最后提出的问题
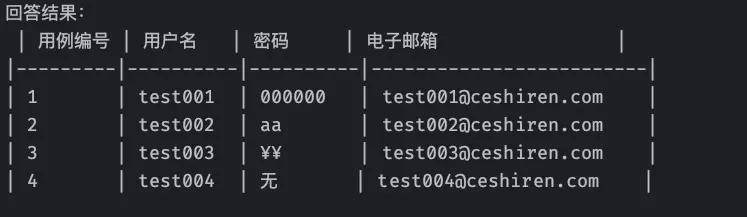
question = "问题:请统计出用户注册用例中,用到的所有用户名、暗码、电子邮箱数据,并将它们列成一个表格"
# 从向量数据库中找到类似度最高的k条文本片段数据
answer_docs = vectordb.similarity_search(query=question, k=4)
# ChatGPT3.5大模型调用实例
llm = ChatOpenAI(temperature=0.0)
# 将向量数据库中检索到的文本片段组装成字符串,做为输入的数据源
resource_doc = "".join([chunk.page_content for chunk in answer_docs])
# 将数据源字符串和问题组装成最后请求大模型的字符串
final_llm_text = f"{resource_doc} {question}"
# 经过大模型获取字符串的回答信息
response = llm.call_as_llm(message=final_llm_text)
print(f"回答结果:\n{response}")
运行结果示例
举荐学习
 返回外链论坛:http://www.fok120.com/,查看更加多 返回外链论坛:http://www.fok120.com/,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-6-30 12:41:06
发表于 2024-6-30 12:41:06



