|
设备之心报告
编辑:张倩 优秀的 GitHub 项目啊!相关 OpenAI ο1 的一切都在这儿
在 AI 行业,OpenAI 已然成为了指路明灯通常的存在。随着 o1 模型的发布,全世界的 AI 工程师都起始了新一轮的学习。
为了帮忙大众尽快抓住重点,设备之心始终在跟进报告关联的诠释,包含: 北大对齐团队独家诠释:OpenAI o1 开启「后训练」时代强化学习新范式张俊林:OpenAI o1 的价值道理及强化学习的 Scaling Law同期,咱们亦发掘了其他有些有用的资源,例如在一个 Github 项目中,有人汇总了近期的高质量技术诠释博客以及「可能」与 o1 技术路线关联的论文。关联资源列表会始终更新,
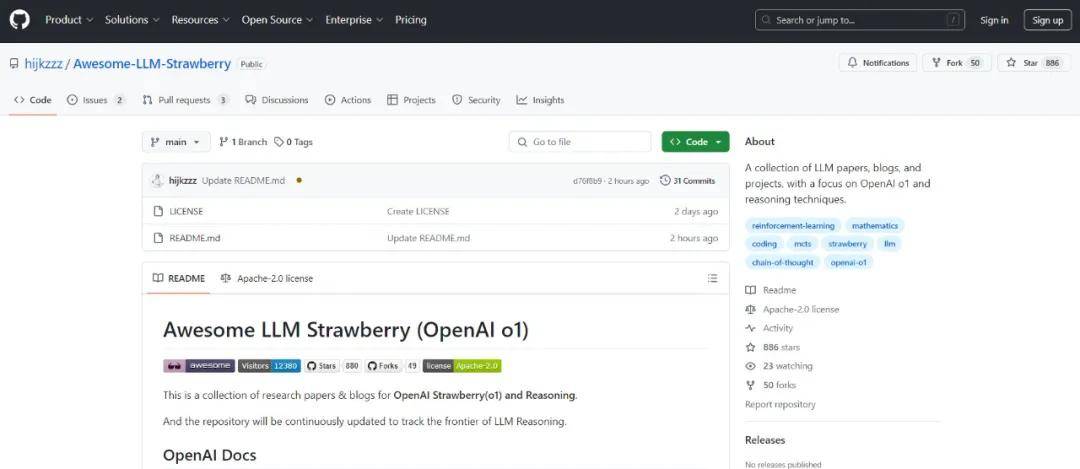
项目链接:https://github.com/hijkzzz/Awesome-LLM-Strawberry这些博客、论文有些是大众都读过的,还有些可能被淹没在平时的众多资源中。或许从中大众能够找到复现 OpenAI o1 的有效办法。
博客 博客 1:Learning to Reason with LLMs作者:OpenAI链接:https://openai.com/index/learning-to-reason-with-llms/博客概述:这篇博客简单介绍了 OpenAI o1 模型的训练办法,例如思维链的采用、模型安全性的提高等。详情请参见设备之心报告:《刚才,OpenAI 震撼发布 o1 大模型!强化学习突破 LLM 推理极限》 博客 2:OpenAI o1-mini作者:OpenAI链接:https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/博客概述:这篇博客介绍了 OpenAI o1-mini 模型的概况。详情请参见设备之心报告:《刚才,OpenAI 震撼发布 o1 大模型!强化学习突破 LLM 推理极限》 博客 3:Finding GPT-4’s mistakes with GPT-4作者:OpenAI链接:https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/博客概述:这篇博客介绍了 CriticGPT——OpenAI 基于 GPT-4 训练的一个专门给 ChatGPT 挑毛病的新模型。它经过精细地分析 ChatGPT 的回答并提出建设性的批评,帮忙人类训练师更准确地评定模型生成的代码,并识别其中的错误或潜在问题。据介绍,在 CriticGPT 的辅助下,人们审查 ChatGPT 代码的准确率加强了 60%。科研人员还发掘,CriticGPT 在非常多状况下比人类专家更善于发掘错误,它们乃至能在有些被认为是「完美无缺」的任务中找出问题,尽管这些任务大都数并不是代码任务,对 CriticGPT 来讲有点超纲。
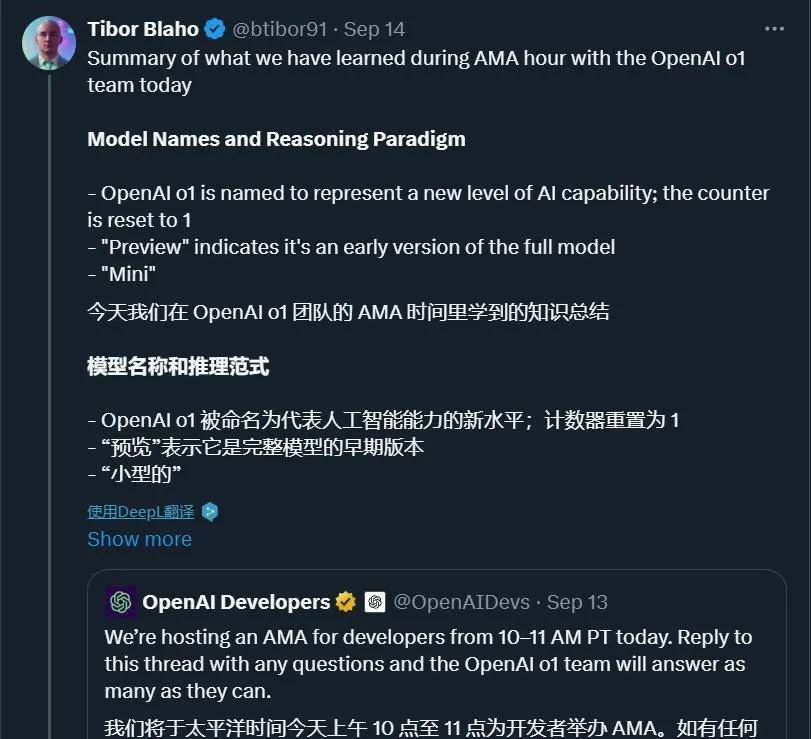
因为该科研发布时,Jan Leike 等 OpenAI 超级对齐团队成员已然离职,因此呢亦被叫作为对齐团队「遗作」。详情请参见设备之心报告:《OpenAI 前对齐团队「遗作」:RLHF 不足用了!用 GPT-4 训练 GPT-4》 博客 4:Summary of what we have learned during AMA hour with the OpenAI o1 team作者:Tibor Blaho链接:https://twitter-thread.com/t/1834686946846597281推文链接:https://x.com/btibor91/status/1834686946846597281博客概述:近期,OpenAI o1 团队开展了一次答疑活动,这个帖子总结了答疑的概要,包含模型命名和推理范式,o1 模型的尺寸和性能,输入 token 上下文和模型能力,工具、功能和即将推出的特性,CoT 推理,API 和运用限制,定价、微调与扩展,模型研发和科研见解,提示技术和最佳实践等几个模块。每一个模块的总结都比较简短,感兴趣的读者能够参见原文。
博客 5:OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference作者:Nathan Lambert(Allen AI 科研专家)链接:https://www.interconnects.ai/p/openai-strawberry-and-inference-scaling-laws博客概述:在文案中,作者讨论了 OpenAI 的新办法「Strawberry」及推理 scaling law,强调了推理计算的投入对 AI 能力提高的重要性。作者指出,扩大推理计算比单纯扩大模型规模更有效,类似 AlphaGo 的推理技术能够明显提高模型表现。文案呼吁将来 AI 研发要更加多关注推理技术。
这篇博客发布于 9 月初,当时 OpenAI 还无发布 o1 模型,因此呢此刻看起来非常有前瞻性。
博客 6:Reverse engineering OpenAI’s o1作者:Nathan Lambert(Allen AI 科研专家)链接:https://www.interconnects.ai/p/reverse-engineering-openai-o1博客概述:这篇博客系统讨论了 OpenAI o1。o1 经过训练新模型处理长推理链,并运用海量强化学习来实现。与自回归语言模型区别,o1 在线为用户搜索答案,展示了新的 scaling law—— 推理 scaling law。博客还讨论了 o1 的有些技术细节,包含其怎样运用强化学习进行训练,以及它在推理时的高成本。另外,博客还探讨了 o1 对将来 AI 行业的影响,包含它怎样改变 AI 制品的安排堆栈和期望,以及它怎样做为一个模型,经过区别的生成策略来实现繁杂的任务。最后,博客提出了有些关于 o1 结构和功能的问题,并讨论了在开源行业复制这种系统所面临的挑战。作者还对 AI 将来的发展方向暗示了期待,认为 AI 的进步将继续奖励哪些敢于想象不可能火速变为可能的人。
论文
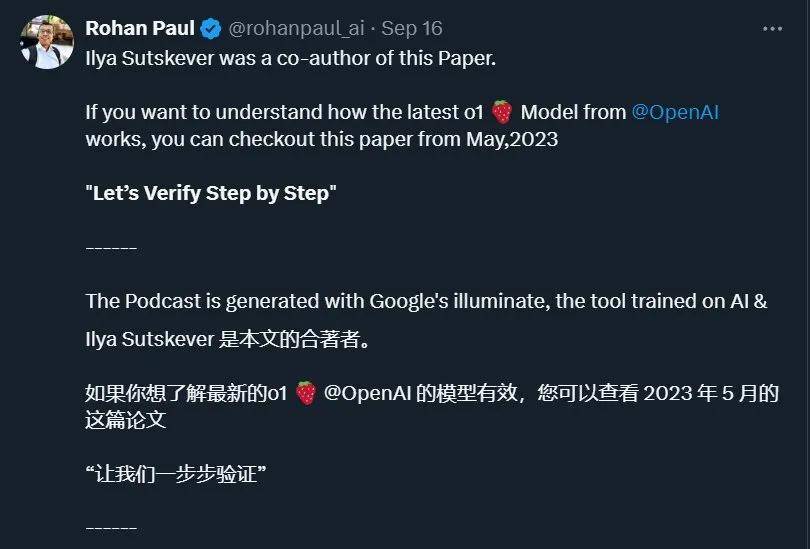
OpenAI o1 贡献者参与撰写的论文 论文 1:Training Verifiers to Solve Math Word Problems公司:OpenAI作者:Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, John Schulman链接:https://arxiv.org/abs/2110.14168论文概述:这篇论文发布于 2021 年 10 月。论文指出,尽管最先进的语言模型在非常多任务上表现优异,但在处理多过程数学推理时仍有困难。为认识决这个问题,作者创建了 GSM8K 数据集,包括 8500 个多样化的小学数学问题。科研发掘,即使是大型 Transformer 模型亦难以在这些任务上取得好成绩。为了加强性能,作者意见训练验证器来评定模型答案的正确性。经过在测试时生成多个答案并选取验证器评分最高的答案,这种办法明显提高了模型在 GSM8K 上的表现,并证明了这种办法比传统的微调办法更有效。 论文 2:Generative Language Modeling for Automated Theorem Proving公司:OpenAI作者:Stanislas Polu, Ilya Sutskever链接:https://arxiv.org/abs/2009.03393论文概述:这篇论文发布于 2020 年 9 月,Ilya Sutskever 是作者之一。论文探讨了基于 Transformer 的语言模型在自动定理证明中的应用。科研的动机是,自动定理证明器与人类相比的一个重点限制 —— 生成原创的数学术语 —— 可能能够经过语言模型的生成来处理。作者介绍了一个名为 GPT-f 的自动证明器和证明助手,用于 Metamath 形式化语言,并分析了其性能。GPT-f 发掘了被 Metamath 重点库接受的新短证明,据作者所知,这是基于深度学习系统首次为形式数学社区贡献并被采纳的证明。 论文 3:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models公司:谷歌大脑作者:Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou链接:https://arxiv.org/abs/2201.11903论文概述:这篇论文发布于 2022 年 1 月。论文探讨了怎样经过生成一系列中间推理过程(即「思维链」)来明显提高挑型语言模型进行繁杂推理的能力。详细来讲,作者提出了思维链提示的办法,即在提示中供给几个思维链的示例,以此来引导模型进行更深入的推理。实验显示,这种办法在三个大型语言模型上加强了算术、常识和符号推理任务的性能。 论文 4:Lets Verify Step by Step公司:OpenAI作者:Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, Karl Cobbe链接:https://arxiv.org/abs/2305.20050论文概述:这篇论文发布于 2023 年 5 月。论文探讨了大型语言模型在繁杂多步推理任务中的表现及其靠谱性问题。作者比较了两种训练办法:结果监督(outcome supervision)和过程监督(process supervision),前者仅对最后结果供给反馈,后者则对每一个推理过程供给反馈。科研发掘,过程监督在训练模型处理 MATH 数据集中的问题时,明显优于结果监督。详细来讲,采用过程监督的模型在 MATH 测试集的一个表率性子集中处理问题的成功率为 78%。另外,论文还展示了主动学习(active learning)在加强过程监督效率方面的重要性。为了支持关联科研,作者还发布了 PRM800K 数据集,这是一个包括 800,000 个过程级人类反馈标签的完整数据集,用于训练她们的最佳奖励模型。
因为包含 Ilya 在内的多位 o1 核心贡献者都参与了这篇论文,有人猜测这是 o1 模型训练的办法论。感兴趣的读者能够重点阅读。亦可参阅设备之心的报告《OpenAI 要为 GPT-4 处理数学问题了:奖励模型指错,解题水平达到新高度》。
论文 5:LLM Critics Help Catch LLM Bugs公司:OpenAI作者:Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, Jan Leike链接:https://arxiv.org/abs/2407.00215论文概述:这篇论文发布于 2024 年 6 月。论文介绍了一种经过训练「批评者」模型(即前面说到的 CriticGPT )来加强人类评定设备学习模型输出的办法。这些批评者模型是大型语言模型,它们被训练来供给自然语言反馈,指出代码中的问题。科研显示,这些模型在识别代码错误方面比人类更有效,乃至能够发掘人类审查者未发掘的错误。尽管存在局限性,如可能产生误导的幻觉错误,但结合人类和设备的团队能够减少这种误导,同期保持错误检测的效率。 论文 6:Self-critiquing models for assisting human evaluators公司:OpenAI作者:William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, Jan Leike链接:https://arxiv.org/pdf/2206.05802论文概述:这篇论文发布于 2022 年 6 月。论文科研了怎样经过微调大型语言模型,运用行径克隆来生成自然语言的批评性评论,以帮忙人类发掘摘要中的缺陷。实验显示,这些模型生成的评论能够揭示人类和设备生成摘要中的问题,包含故意误导的错误。科研发掘,更大的模型在撰写有帮忙的评论和自我批评方面表现更好,并且能够利用自我批评来改进自己的摘要。论文还提出了一个比较批评能力、生成能力和辨别能力的框架,并指出即使是大型模型亦可能有未表达的知识。这项科研为运用人工智能辅助的人类反馈来监督设备学习系统供给了概念验证,并公开了训练数据集和实验样本。
其他论文
除了以上论文,作者还根据年份列出了有些可能与 OpenAI o1 关联的论文,列表如下:
2024 年:


2023 年:

2022 年:

2021 年:

2017 年:

更加多信息请参见原 GitHub 库。返回外链论坛: http://www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-10-3 05:30:10
发表于 2024-10-3 05:30:10










