|
液体活检被认为是一种成本效益高且没创的技术,能够在初期发掘癌症,对个体进行归类以进行定制治疗,并快速衡量治疗方法是不是成功。它依赖于非固体样本的取样,重点是血液,并进一步分离循环肿瘤细胞和/或其他肿瘤衍生物质(例如循环肿瘤DNA、外泌体等)。尽管拥有显著的优良,但成功实施该办法必须过滤、分离和/或实时监测生物标志物,浓度为每1−10mL血液,周边有6 × 106个白细胞、2 × 108个血小板和4 × 109个红细胞,这使其作为一项非常拥有挑战性的任务。利用液体活检中存在的某些生物学特性来检测和分析抗原被证明是困难的,但仍然是可行的。
在肺癌的体外科研中,利用VOC进行鉴定的准确率达到90%,它在初期发掘一系列癌症和转移的准确率分别为> 84%和97%。虽然这些结果证明了经过基于挥发性有机化合物的液体活检进行癌症没创诊断的快速、易于运用和低价工具的可行性,但更高的准确性将引起更有效的诊断和监测,从而加强存活率。
2023年3月,ACS Sensors在线发布了一篇利用GC-MS和传感器分析肾癌、肺癌和胃癌三种不同癌症病人血液中的挥发性有机物,在以上三种癌症疾患诊断方面创立数据模型。科研结果显示:
GC-MS和传感器阵列分析能够测绘人类血液和尿液样本中的癌症特异性VOCs,以检测和区分癌症和对照组、不同类型的癌症和不同周期的特定癌症,准确度>90%,灵敏度>80%,特异性>80%。血液和尿液的联合分析加强了区分能力,使模型的准确率加强了>3%。另外,该方式亦可用于在很长一段时间内跟踪疾患的发展。

技术路线
1. 三组癌症病人的血液和尿液活检液:肾癌KC (N = 101)、肺癌LC (N = 26)和胃癌GC (N = 26),以及一组健康对照组(N = 152),其中包含22名有胃癌症状的对照组(FG)。
2. 采用了两种办法来检测:运用气相色谱-质谱(GC - MS)检测和鉴定每一个样品顶空中挥发性有机化合物的化学性质和构成;基于实验室的有机保留的小金纳米颗粒(GNPs,核心直径3 - 4 nm)的化学阵列,单壁碳纳米管(RN-SWCNTs)的二维随机网络,以及聚合物和ML办法的组合来识别和归类VOC模式。
科研结果
1. GC-MS检测及结果分析
利用GC-MS技术在所有分析的血液和尿液样本中检测到>100个VOCs。从这些VOCs中筛选出64种VOCs(存在于超过70%的人群中,且其在环境空气样本中的浓度比同等血液或尿液样本中的浓度低10倍以上)。有些挥发性有机化合物在血液和尿液中很平常,有些则否则,这些差异可能是因为不准确的初步鉴定。因此呢经过随机森林(RF)和分层聚类办法对筛选的挥发性有机化合物进一步分析,在血液和尿液样本的数据上构建了这些模型,并将血液和尿液样本的数据合并在一块,比较了所有模型的结果和性能。
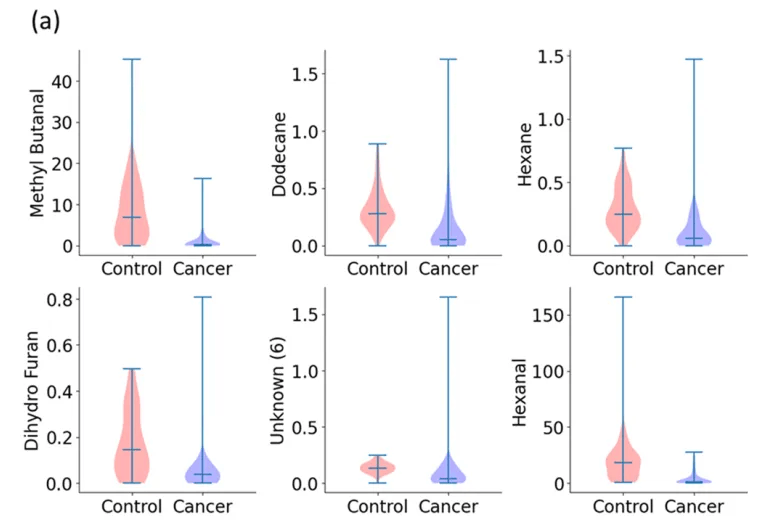
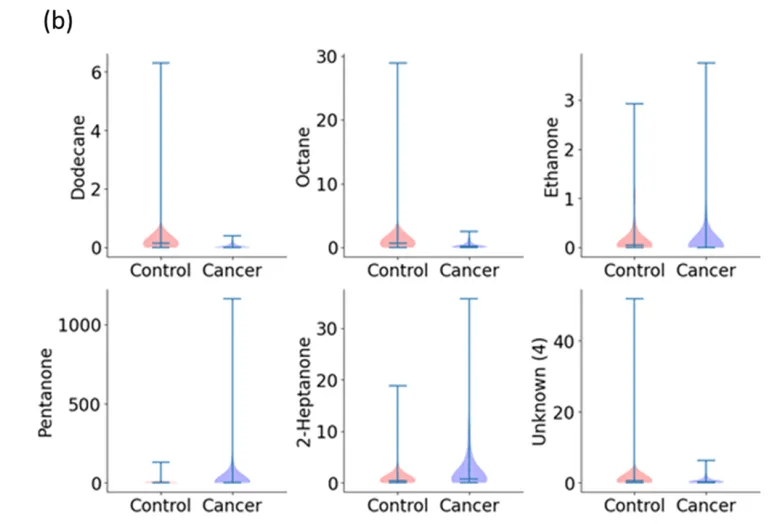
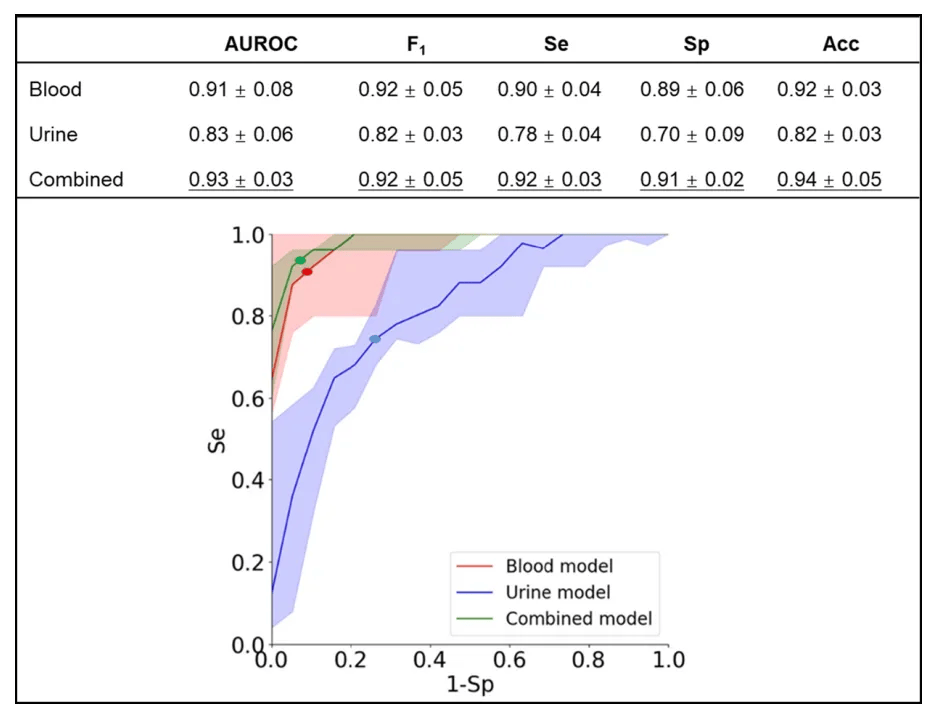
第1步首要分析所有类型的癌症(即所有癌症类型做为一组)和对照组之间的二元归类。Wilcoxon秩和检验表示,血液数据有26个特征p < 0.05(图1a,血液数据中区分癌症组和对照组最具区分性的六种挥发性有机化合物),尿液数据有16个特征p小于阈值(图1b,尿液数据中六种最具区分性的挥发性有机化合物)。基于这些VOCs, RF模型在血液样本中表示出更高的准确性/灵敏度/特异性(92/ 90/89%),尿液模型相对偏低(82/78/70%;图2)。
■ ■ ■ ■ ■
图1. 血液和尿液中典型VOC小提琴图
对血液和尿液VOC数据集的综合分析改善了所有参数,并表示出癌症组和对照组之间的最高区分值:准确率94%,灵敏度92%,特异性91%(图2)。这些改进的结果可归因于在训练模型时数据的维度更高(即特征数量更加多)。
■ ■ ■ ■ ■
图2. 不同数据集ROC分析
利用以上模型针对特定癌症的检测进行测试,测试结果如下:

结合血液和尿液两种数据,将血液和尿液的归类准确率分别从0.91±0.08和0.83±0.06加强到0.93±0.03。加入年龄、性别和吸烟情况等人口统计学特征将使基于血液和尿液数据的模型的受试者工作特征曲线(AUROC)下面积增多0.02,F1分数(即精度和召回率的调和平均值,可做为准确性的衡量标准)增多0.01。这些模型的准确性显著较低,可能受到每一个类别中样本数量较少的影响。以血液为基本的模型比以尿液为基本的模型更好,并且两种源自的组合并无提高它们的性能。
在许多状况下,研发的模型能够检测和区分不同周期的癌症。然则因为用于测试的255名病人中仅有87名病人的癌症分期信息,且每一个周期的病人数量较少(分别为16例和19例),没法从中得出任何结论,亦没法训练任何模型来预测癌症周期。然则在其他状况下,研发的模型能够区分身患癌症的受试者和有胃癌症状的受试者,在这个检测示例中,血液模型比尿液模型表示出更高的准确性,分别为92%和88%。测试模型的灵敏度较低(两种模型均为33%),不像血液模型的100%和尿液模型的95%的高特异性。联合模型改善了所有性能指标,并表示出最高的识别准确率、灵敏度和特异性(分别为96%、66%和100%)。
为了科研所检查的组之间的关系进行了分层聚类分析(Ward最小方差法),结果表示在血液树形图和星座图中,健康对照和KC受试者显著是掰开聚类的,而其他较小的实验组无聚类,而是被同化到很强的组中(图3a,b)。尿液VOC样本的聚类效果较差,并且大都数VOC无聚集到不同的亚组中(图3c,d)。结合血液和尿液两组数据改善了聚类(图3e,f),这是经过观察GC, LC和FG组除了健康对照和KC两个重点聚类外的联合亚组来表达的(图3e)。运用每组中每一个VOC的平均丰度而不是原始数据进行分层聚类,能够明显改善聚类。有趣的是,血液和尿液样本中VOC的平均丰度数据集的组合完美地聚集了单独的两组。健康对照组和FG组做为亚组聚在一块,不同癌症类型分别聚在一块。
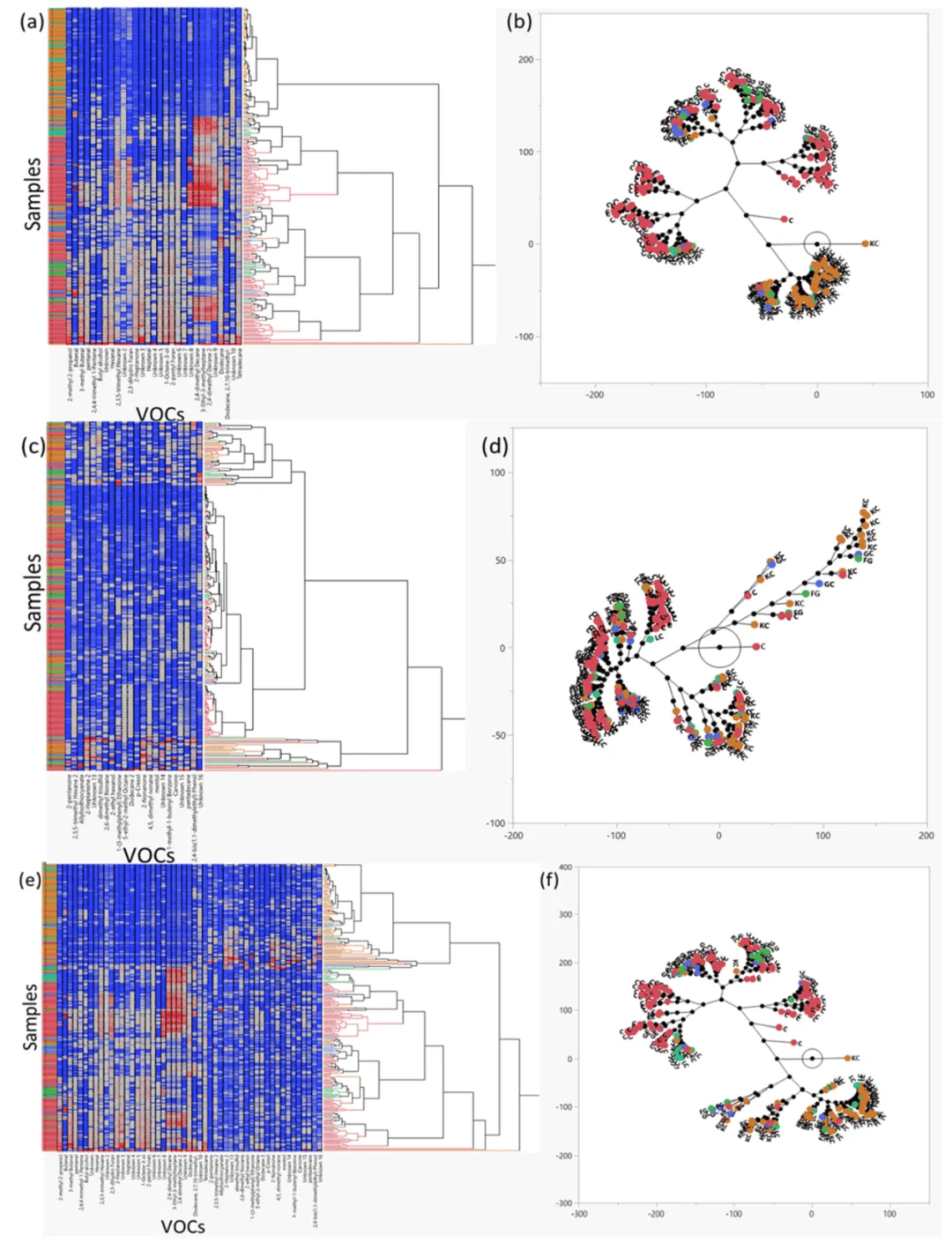
■ ■ ■ ■ ■
图3. 分层聚类和相应的星座图
2. 基于实验室的传感器阵列分析
将血液和尿液顶空样本暴露于传感器阵列后,对610份样本(305份尿液和305份血液)进行了判别函数分析(DFA),其中153份来自确诊癌症病人,152份来自对照组。为了评定二次DFA模型的有效性,随机选取盲测组30%的数据集被运用。
与GC-MS模型同样,首要将所有癌症病例分组为一个“癌症”组,将FG和健康个体分组为“对照组”。针对这两组研发了单独分析血液样本、单独分析尿液样本或血液和尿液组合数据集的模型。所选特征的平均原始数据的雷达图表示了传感器对癌症组或对照组反应的差异。雷达图中的每一个点表率DFA选取的传感特征的真实值(全部关联组的平均值)。点之间的连接创建了一个雷达图,能够在选取的组之间进行直观的比较,而没需将数据更改为不同的维度(图4a)。在DFA的训练周期,血液(准确性93.3%,敏锐性88.5%,特异性98%)和尿液(准确性86.1%,敏锐性95.8%,特异性76.7%)中所有三种模型的结果都得到了高分。联合模型供给了88.7%的准确度,95.8%的灵敏度和81.6%的特异性,这些值与VOC相比无表示出任何改善。盲测组(30%)的分析结果更好,联合模型的准确性、敏锐性和特异性分别加强了97.6、97.7和97.4%。
进一步针对不同类型癌症(GC、KC和LC)的区分分析显示,每种癌症都有其独特的传感器阵列,因此呢能够用于区分不同类型的癌症(图4b-d)。不同模型的训练集的准确率在75 ~ 91.5%之间,而测试集的准确率在80 ~ 100%之间。组合模型始终表现出较好的性能。例如,血液中区分KC和GC的准确率为92%,尿液中区分KC和GC的准确率为91.6%,在联合模型中达到97.2%。
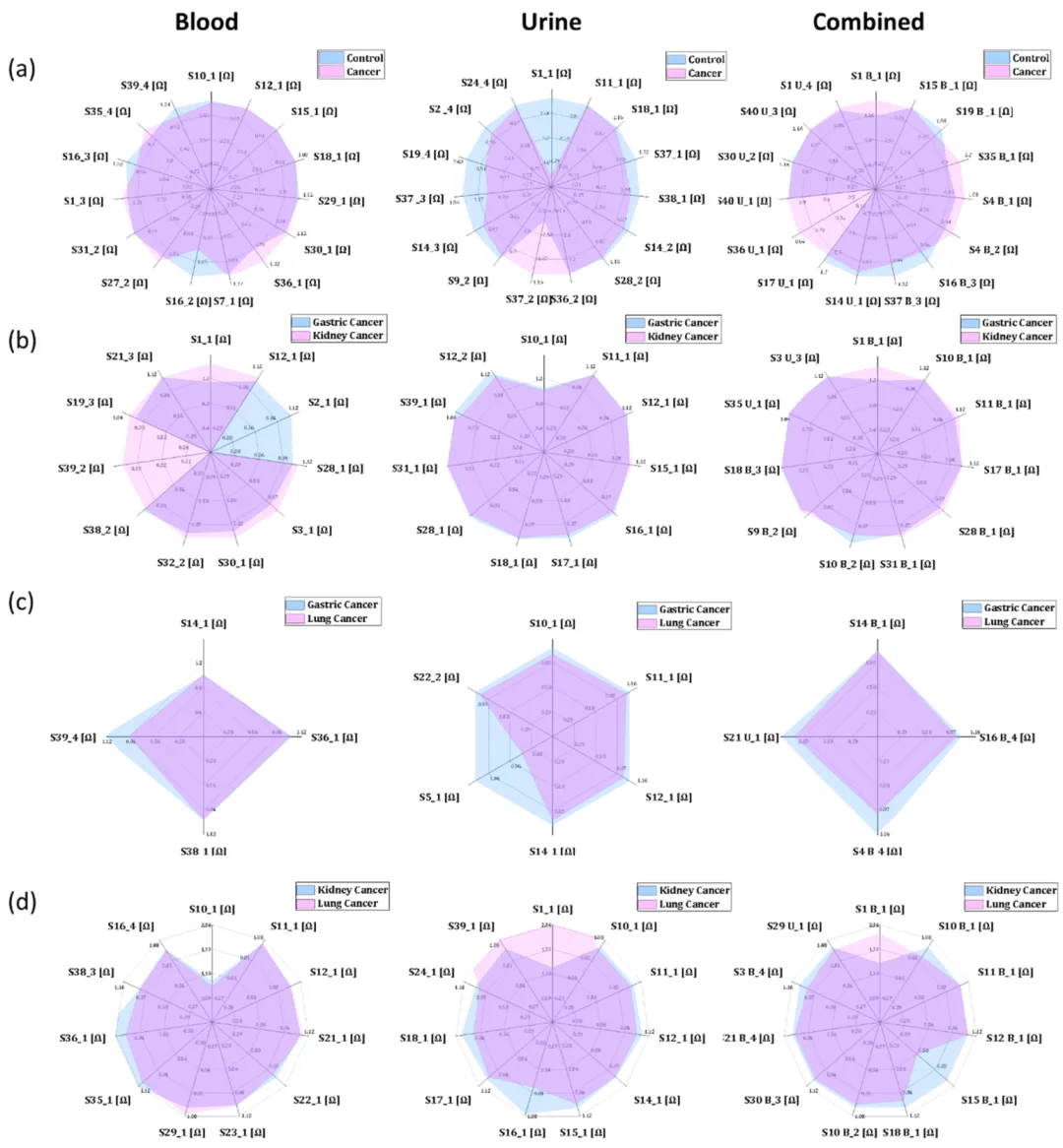
■ ■ ■ ■ ■
图4. 传感器数据雷达图
为了保证分析不因混杂原因影响而产生偏差,作者检测了年龄、性别和吸烟情况对癌症组和对照组得到的诊断和鉴别结果的影响。结果显示因为一个或多个混杂原因,癌症组和对照组之间的差别在30%到56.6%之间,即大部分是任意的。对每一个癌症组的类似分析显示,因为混杂原因引起的区分准确率为~ 50%,即无迹象显示混杂原因对模型性能有影响。假设不均匀的群体规模和原因分布引起了这些数字,因此呢,应该收集更平衡的数据,以便能够忽略这些原因。另外,在混杂原因确实影响诊断的状况下,应计算其权重并将其纳入诊断模型研发。返回外链论坛:http://www.fok120.com/,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-6-22 13:58:43
发表于 2024-6-22 13:58:43








