|
设备之心报告
编辑:泽南、小舟 最多可支持 10000+ 个并发线程。经过近 10 年的不懈奋斗,对计算机科学核心的深入科研,人们最终实现了一个梦想:在 GPU 上运行高级语言。
上周末,一种名为 Bend 的编程语言在开源社区诱发了热烈的讨论,GitHub 的 Star 量已然超过了 8500。

GitHub:https://github.com/HigherOrderCO/Bend
做为一种大规模并行的高级编程语言,它仍处在科研周期,但提出的思路已然让人们感到非常惊讶。运用 Bend,你能够为多核 CPU/GPU 编写并行代码,而无需作为拥有 10 年经验的 C/CUDA 专家,感觉就像 Python 同样!
是的,Bend 采用了 Python 语法。
与 CUDA、Metal 等低级替代方法区别,Bend 拥有 Python、Haskell 等表达性语言的功能,包含快速对象分配、完全闭包支持的高阶函数、无限制的递归,乃至 continuation。Bend 运行在大规模并行硬件上,拥有基于核心数量的近线性加速。Bend 由 HVM2 运行时供给支持。
该项目的重点贡献者 Victor Taelin 来自巴西,他在 X 平台上分享了 Bend 的重点特性和研发思路。
首要,Bend 不适用于现代设备学习算法,由于这些算法是高度正则化的(矩阵乘法),拥有预先分配的内存,并且一般已然有编写好的 CUDA 内核。
Bend 的巨大优良表现在实质应用中,这是由于「真正的应用程序」一般无预算来制作专用的 GPU 内核。试问,谁在 CUDA 中制作了网站?况且,即使有人这般做了,亦是不可行的,由于:
1. 真正的应用程序必须从许多区别的库导入函数,没法为它们编写 CUDA 内核;
2. 真实的应用程序具有动态函数和闭包;
3. 真实的应用程序会动态且不可预测地分配海量内存。
Bend 完成为了有些新的尝试,并且在某些状况下能够相当快,但此刻想写大语言模型肯定是不行的。
作者对比了一下旧办法和新的办法,运用相同的算法树中的双调排序,触及 JSON 分配和操作。Node.js 的速度是 3.5 秒(Apple M3 Max),Bend 的速度是 0.5 秒(NVIDIA RTX 4090)。
是的,日前 Bend 必须整块 GPU 才可在一个核心上击败 Node.js。但另一方面,这还是一个初生的新办法与大机构(Google)优化了 16 年的 JIT 编译器在进行比较。将来还有非常多可能性。
怎样运用
在 GitHub 上,作者简要介绍了 Bend 的运用流程。
首要,安装 Rust。倘若你想运用 C 运行时,请安装 C 编译器(例如 GCC 或 Clang);倘若要运用 CUDA 运行时,请安装 CUDA 工具包(CUDA 和 nvcc)版本 12.x。Bend 日前仅支持 Nvidia GPU。
而后,安装 HVM2 和 Bend:
cargo +nightly install hvm
cargo +nightly install bend-lang
最后,编写有些 Bend 文件,并运用以下命令之一运行它:
bend run <file.bend> # uses the Rust interpreter (sequential)
bend run-c <file.bend> # uses the C interpreter (parallel)
bend run-cu <file.bend> # uses the CUDA interpreter (massively parallel)
你还能够运用 gen-c 和 gen-cu 将 Bend 编译为独立的 C/CUDA 文件,以得到最佳性能。但 gen-c、gen-cu 仍处在起步周期,远无像 GCC 和 GHC 这般的 SOTA 编译器那样成熟。
Bend 中的并行编程
这儿举例说明能够在 Bend 中并行运行的程序。例如,表达式:
(((1 + 2) + 3) + 4)
不可并行运行,由于 + 4 取决于 + 3,而 + 3 又取决于 (1+2)。而表达式:
((1 + 2) + (3 + 4))
能够并行运行,由于 (1+2) 和 (3+4) 是独立的。Bend 并行运行的要求便是符合并行规律。
再来看一个更完整的代码示例:
# Sorting Network = just rotate trees!
def sort (d, s, tree):
switch d:
case 0:
return tree
case _:
(x,y) = tree
lft = sort (d-1, 0, x)
rgt = sort (d-1, 1, y)
return rots (d, s, lft, rgt)
# Rotates sub-trees (Blue/Green Box)
def rots (d, s, tree):
switch d:
case 0:
return tree
case _:
(x,y) = tree
return down (d, s, warp (d-1, s, x, y))
该文件实现了拥有不可变树旋转的双调排序器。它不是非常多人期望的在 GPU 上快速运行的算法。然而,因为它运用本质上并行的分治办法,因此呢 Bend 会以多线程方式运行它。有些速度基准: CPU,Apple M3 Max,1 个线程:12.15 秒 CPU,Apple M3 Max,16 线程:0.96 秒 GPU,NVIDIA RTX 4090,16k 线程:0.21 秒不执行任何操作就可实现 57 倍的加速。无线程产生,无锁、互斥锁的显式管理。咱们只是需求 Bend 在 RTX 上运行咱们的程序,就这么简单。
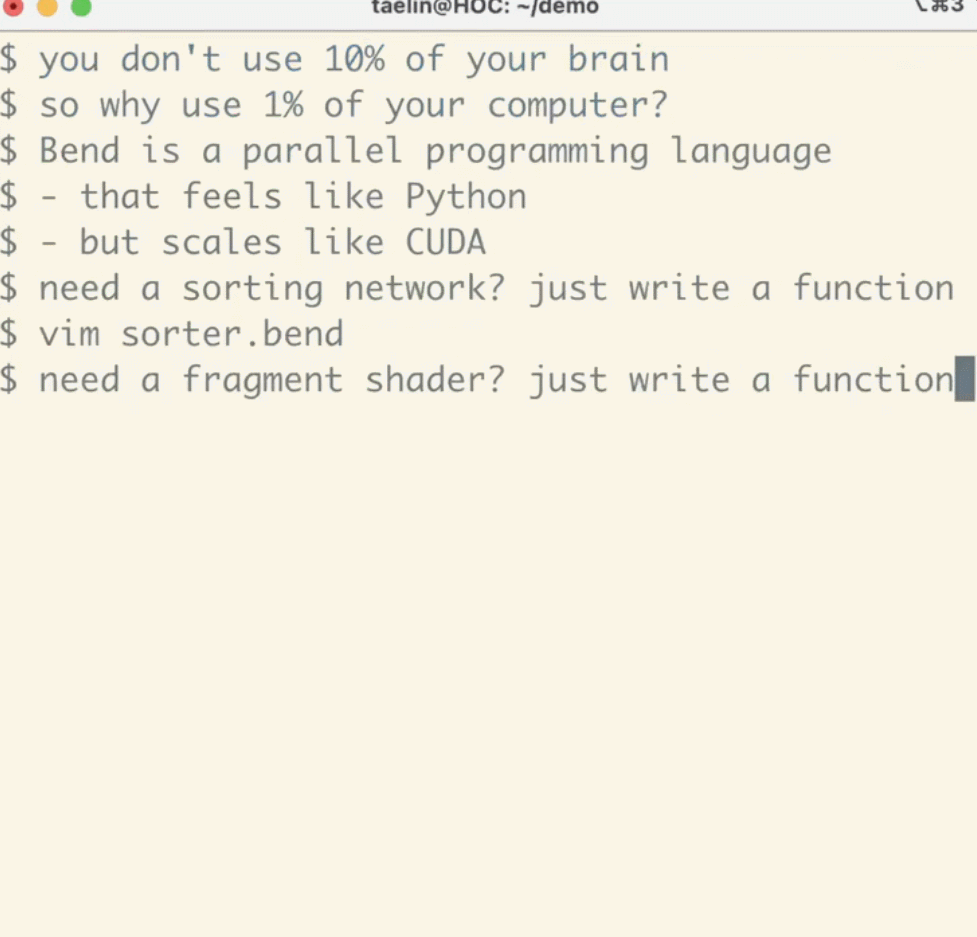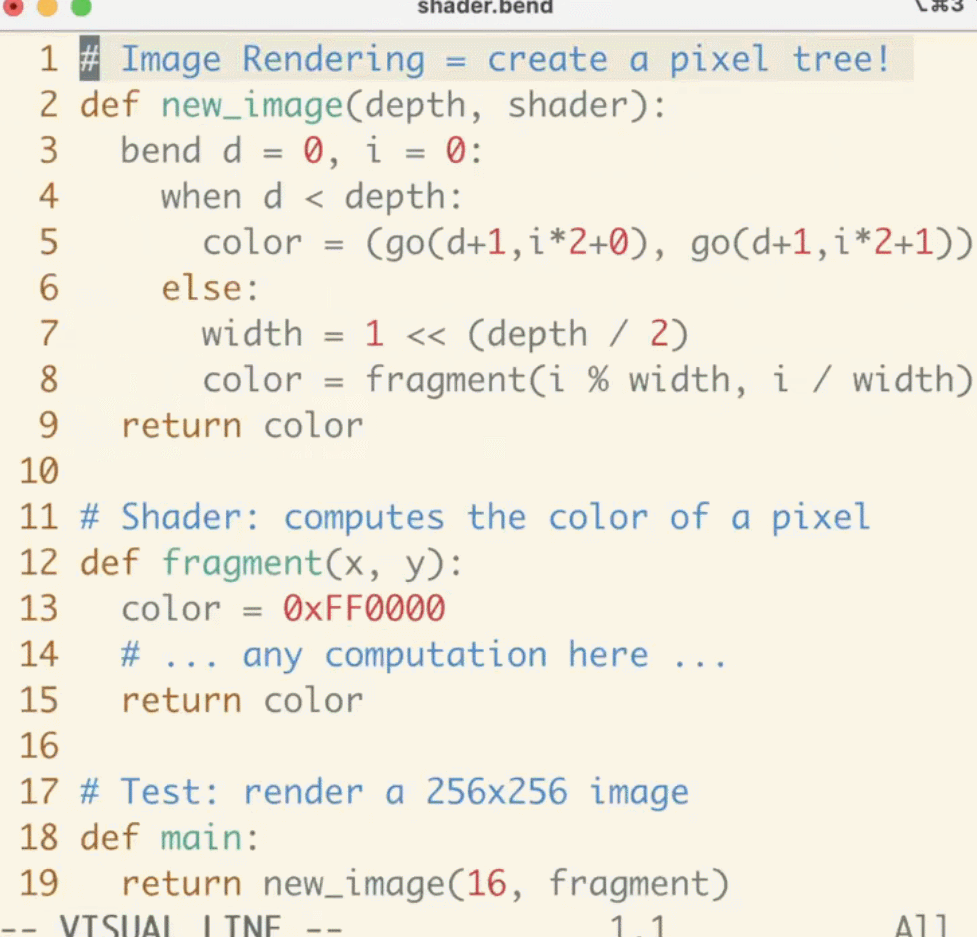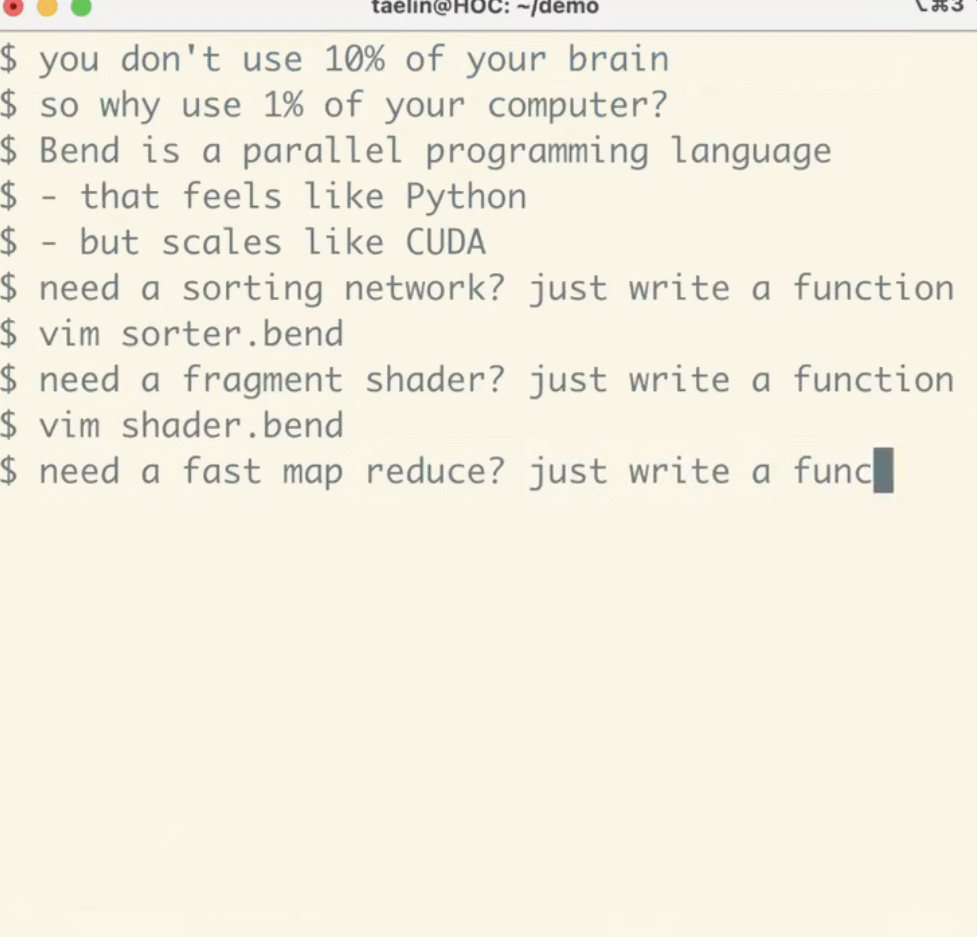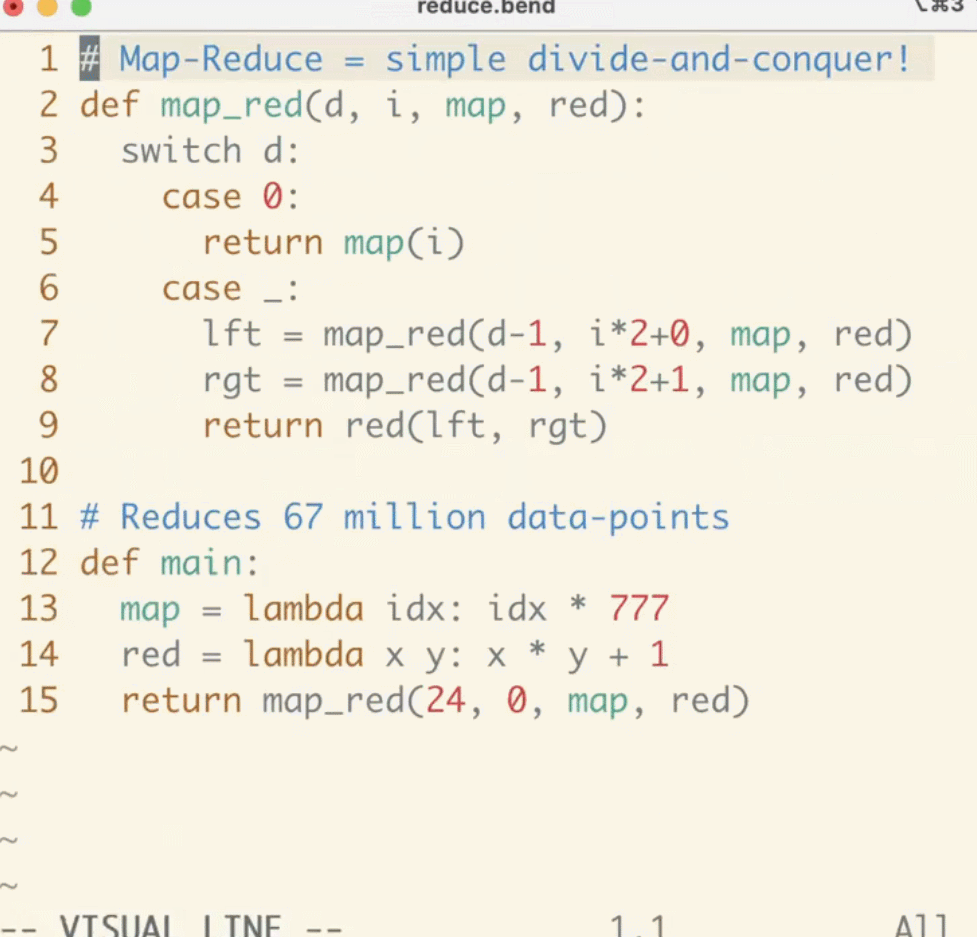
Bend 不限于特定范例,例如张量或矩阵。任何的并发系统,从着色器到类 Erlang 的 actor 模型都能够在 Bend 上进行模拟。例如,要实时渲染图像,咱们能够简单地在每一个帧上分配一个不可变的树:
# given a shader, returns a square image
def render (depth, shader):
bend d = 0, i = 0:
when d < depth:
color = (fork (d+1, i*2+0), fork (d+1, i*2+1))
else:
width = depth / 2
color = shader (i % width, i /width)
return color
# given a position, returns a color
# for this demo, it just busy loops
def demo_shader (x, y):
bend i = 0:
when i < 5000:
color = fork (i + 1)
else:
color = 0x000001
return color
# renders a 256x256 image using demo_shader
def main:
return render (16, demo_shader)
它确实会起功效,即使触及的算法在 Bend 上亦能很好地并行。长距离通信经过全局 beta 缩减(按照交互演算)执行,并经过 HVM2 的原子链接器正确有效地同步。
最后,作者暗示 Bend 此刻仅仅是第1个版本,还无在合适的编译器上投入太多精力。大众能够预期将来每一个版本的原始性能都会大幅加强。而此刻,咱们已然能够运用解释器,从 Python 高级语言的方向一睹大规模并行编程的样子了。
参考内容:
https://news.ycombinator.com/item?id=40390287
https://x.com/VictorTaelin?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
https://x.com/DrJimFan/status/1791514371086250291返回外链论坛:www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-8-17 14:38:59
发表于 2024-8-17 14:38:59

