|
现如今,随着人们生活方式和环境的改变,恶性肿瘤已然作为疾患死亡病因之一。肿瘤在全世界呈现发病率升高,以及发病年龄青年化的趋势。 2019年, A Cancer Journal For Clinicians 杂志颁布了最新的数据。 该报告估计, 2019年美国将有1,762,450例新的癌症病例和606,888例与癌症关联的死亡。
传统化疗是对抗癌症的平常办法,但它会攻击全身,导致不必要的副功效,如脱发,恶心和疲劳。 靶向治疗选取性地杀死癌细胞而不影响健康组织。 靶向药品研发将作为治疗癌症的要紧手段。
高通量检测技术快速发展,使得与肿瘤关联的组学数据快速累积。 这些数据针对科研肿瘤的出现发展机制拥有要紧道理。 对数据的挖掘能够确定许多与疾患相关的基因,为治疗和发病机制的科研供给新的思路。 怎样有效利用和存储这些信息就显出尤为要紧。 肿瘤的生物信息学数据库 的创立供给了有效的处理方法,对肿瘤基本科研的发展、临床治疗水平的加强拥有极重的推动功效。
以下是博主为大众整理的有些肿瘤关联的数据库归类和大致信息:
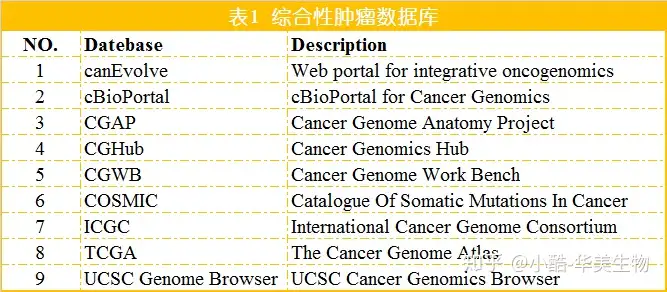
1.综合性肿瘤数据库
2.肿瘤基因组数据库
3.肿瘤DNA甲基化数据库
4.肿瘤转录组数据库
5.肿瘤蛋白组数据库
6.肿瘤关联基因的数据库
7.肿瘤与药品数据库
1.综合性肿瘤数据库
1.1canEvolve[1]canEvolve存储的信息包含:基因、microRNA (miRNA)和蛋白质表达谱、多种癌症类型的拷贝数变化(CNAs)以及蛋白质-蛋白质相互功效信息。
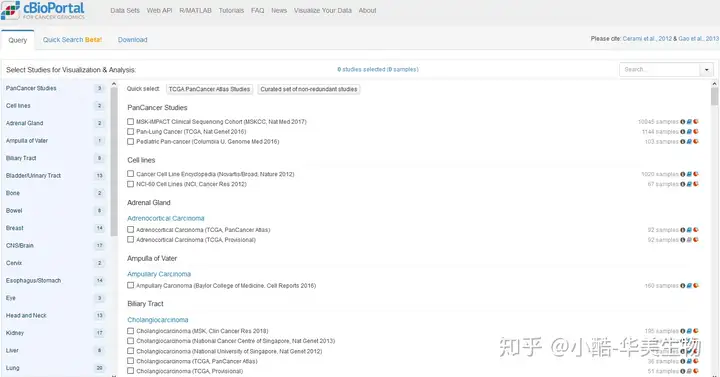
1.2cBioPortal for Cancer Genomics(cBioPortal)[2]cBioPortal for Cancer Genomics是一个癌症基因组数据探索、可视化及分析平台,可用于多个癌症基因组学数据集的交互式探索。该数据库可供给CNA、基因突变信息。针对每一个基因,它可给出多个信息,重点包含:基因的CAN信息、基因突变在样本中的分布、突变位点和频率、共表达基因以及存活曲线等。针对用户供给的基因列表,还可生成互作网络并供给已知的相互功效的药品。cBioPortal在发掘肿瘤关联突变、分析基因的生物学功能以及药品选择等方面的科研中拥有要紧推进功效。
△ cBioPortal数据库的主页
1.3Cancer Genome Anatomy Project(CGAP)[3]CGAP网重点供给了cDNA克隆、文库、基因表达、SNP以及基因组变异等信息。CGAP收集的数据包含正常组织、前癌组织以及癌细胞的基因表达水平。
1.4Cancer Genomics Hub (CGHub)[4]CGHub是美国国家癌症科研所(NCI)测序项目的在线存储库,其数据源自包含癌症基因组图谱(TCGA)、癌症细胞系百科全书(CCLE)和产生有效治疗(目的)项目的治疗应用科研(TARGET)3个国家癌症协会项目,数据来自25种不同类型的癌症。
1.5Cancer Genome Work Bench (CGWB)[5]CGWB供给了一系列工具来挖掘、整合以及可视化TCGA等数据库中的基因组和临床数据,它是第1个将临床肿瘤突变谱与参考人类基因组整合在一块的计算平台。用户可快速地比较病人临床信息与基因组的变异及甲基化等。
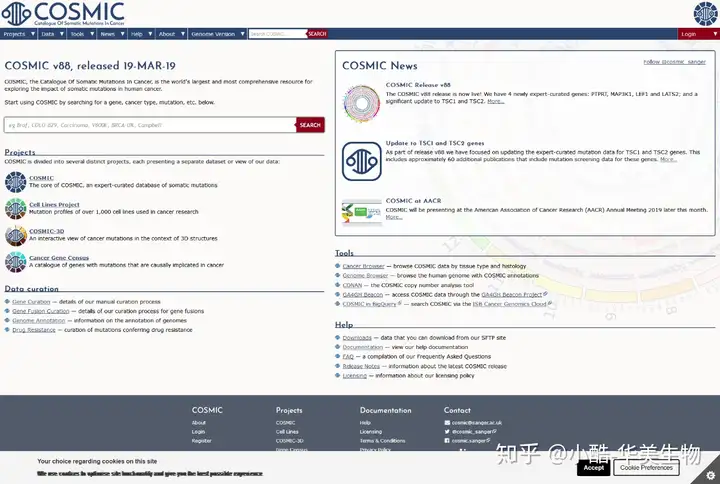
1.6Catalogue of Somatic Mutations inCancer (COSMIC)[6]COSMIC是世界上最大最全面的相关肿瘤的体细胞突变以及其影响的资源库。它重点供给多种肿瘤细胞基因组中的CNA、甲基化、基因融合、SNP及基因表达等信息。这些突变信息是从科学文献中手工整理的。
1.7InternationalCancer Genome Consortium (ICGC)[7]ICGC的目的是获取包含胆道癌、膀胱癌、血癌等多达50种肿瘤及其亚型的基因组、转录组和表观遗传的所有信息。这些数据可促进癌症的机理和治疗科研。
1.8The Cancer Genome Atlas (TCGA)[8]TCGA是由于美国国立癌症科研所(NCI)和国家人类基因组科研所帮助,关注与癌症的出现和发展关联的分子突变图谱。该数据库重点对样本进行外显子组和基因组测序分析,所供给的数据包含:基因组拷贝数变化、表观遗传、基因表达谱、miRNA等。
1.9UCSC Cancer Genomics Browser[9]UCSCCancer Genomics Browser是一个能够对癌症基因组学和临床数据进行整合、可视化、分析的网络分析工具。它保留癌症基因组及临床数据并收集了样本的多种信息,包含基因表达水平、CNA、通路信息等。在UCSC的癌症基因组浏览器中,可实现不一样本以及癌症类型之间的比较,分析基因组变异与表型之间的关联性。
2.肿瘤基因组数据库
肿瘤细胞的基因组中都存在着海量的变异,重点包含染色体结构的变异、CNA、基因融合以及SNP等。拷贝数改变(CNAs)在很大程度上有助于癌症发病机制和发展。肿瘤基因组数据库汇总如表2所示。
2.1ArrayMap[10]ArrayMap供给预处理过的肿瘤基因组芯片数据以及CNA图谱。在ArrayMap数据库中,用户可搜索自己感兴趣的样本,并这里基本上分析感兴趣的基因或基因组片段上的CNA;用户还能够比较两个样本之间的CNA的差异。
2.2BioMuta[11]BioMuta数据库存储了癌症细胞中基因的非同义单核苷酸变异,这些突变会影响基因的正常功能。BioMuta中的数据源自于COSMIC、ClinVar、UniProtKB以及有些文献中。用户可搜索感兴趣的基因,得到该基因在癌细胞中的突变位点及其分布频率。
2.3Cancer GEnome Mine (CanGEM)[12]CanGEM是一个公共的数据库,用于存储定量微阵列数据和临床肿瘤样本数据。它重点利用ArrayCGH芯片来发掘基因的拷贝数变异。
2.4Cancer Genome Project (CGP)[13]CGP供给了肿瘤中的CNA及基因型信息,该数据库的重点目的是利用人类基因组序列和高通量的突变检测技术识别体细胞突变,从而发掘人类肿瘤出现过程中要紧的基因。该数据库还供给了有些识别突变、CNA的软件,如BioView、GRAFT等。
3.肿瘤DNA甲基化数据库
DNA甲基化修饰是表观遗传学的一种要紧形式,它调节基因的转录水平,对维持细胞的正常功能起着要紧功效。DNA甲基化模式的改变可能引起癌症。肿瘤DNA甲基化数据库汇总如表3所示。
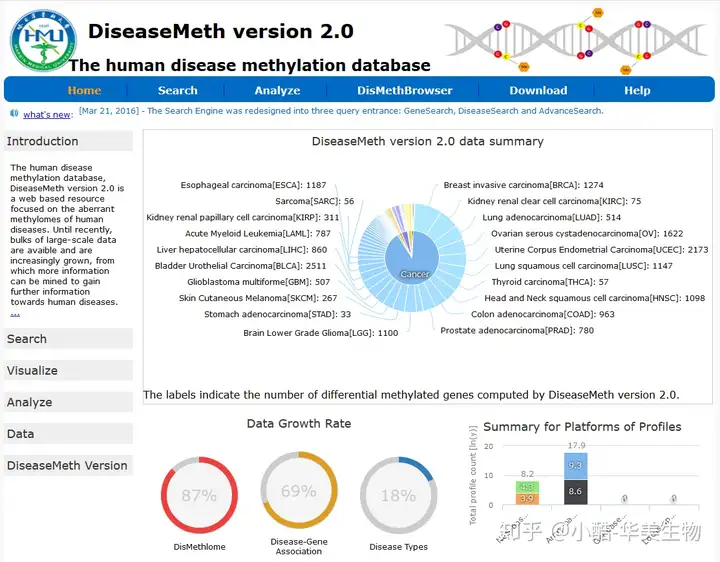
3.1DiseaseMeth[15]DiseaseMeth是一个人类疾患甲基化数据库,其重点是对各样疾患的DNA甲基化数据集进行有效的存储和统计分析。它触及的疾患包含癌症、神经生长和退行性疾患、自己免疫疾患等。在DiseaseMeth中能够比较疾患与疾患之间、基因与基因之间以及疾患与基因之间的甲基化关系。
3.2MENT[16]MENT数据库收集和整合了来自GeneExpression Omnibus(GEO)和TCGA的DNA甲基化、基因表达水平数据,同期将DNA甲基化和基因表达水平相关起来。
3.3MethHC[17]MethHC是一个集成数据库,包括海量DNA甲基化数据和mRNA/microRNA在人类癌症中的表达谱。这些数据能够帮忙科研人员确定表观遗传模式。
3.4MethyCancer[18]该数据库持有来自公共资源的高度整合的DNA甲基化数据、癌症关联基因、突变和癌症信息,以及咱们大规模测序得到的CpGIsland (CGI)克隆。MethyCancer可用于科研DNA甲基化、基因表达与癌症的相互功效。
除了以上针对癌症基因组甲基化的数据库外,还有有些数据库搜集和整理更为广泛的甲基化数据,如MethDB和NGSmethDB。
MethDB 是较早的DNA甲基化数据库,重点集中于环境因子对甲基化的影响;
NGSmethDB 基于高通量测序数据,近期更新中还包括了SNP信息,以便后续分析。
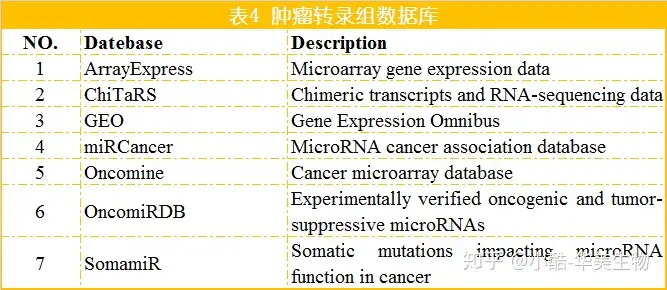
4.肿瘤转录组数据库
肿瘤细胞拥有较强的生长和繁殖能力,生命活动旺盛,因此呢与正常细胞相比,基因的转录水平和模式亦存在很强的差异。
4.1ArrayExpress[19]ArrayExpress是基于微阵列和高通量测序(HTS)的功能基因组实验的重点知识库之一。ArrayExpress中的所有数据都以MAGE-TAB格式供给。
4.2ChiTaRS[20]ChiTaRS数据库包括嵌合转录本和RNA-Seq数据。ChiTaRS嵌合转录本和RNA-Seq数据数据库是由于GenBank、ChimerDB、dbCRID、TICdb和其他用于人类、小鼠和苍蝇的数据库的表达序列标记(ESTs)和mRNA识别的嵌合转录本集合。
4.3Gene Expression Omnibus (GEO)[21]GEO是由于美国国家生物技术信息中心(NCBI)创立的,其最初的目的是做为一个公共存储库,存储重点由微阵列技术生成的高通量基因表达数据。另外,该数据库还包含比较基因组分析、描述基因组蛋白相互功效的染色质免疫沉淀分析、非编码RNA分析、SNP基因分型和基因组甲基化状态分析。
4.4miRCancer[22]miRCancer基于从文献中提取的结果,供给了较为全面的miRNA集合以及它们在多种肿瘤中的表达状况。所有miRNA的癌变相关都是在自动提取后手动确认的。
4.5Oncomine[23]Oncomine重点供给癌症转录组数据。它可供给基因在肿瘤样本和正常样本间、肿瘤样本和肿瘤样本间、正常样本和正常样本间的差异表达、基因表达谱、共表达基因等信息。
4.6OncomiRDB[24]OncomiRDB重点收集和注释经过实验验证的对癌症拥有促进或控制功效的miRNA信息。该数据库的所有数据是经过人工收集和整理。
4.7SomamiR[25]SomamiR数据库集成为了多种类型的数据,用于科研体细胞和种系突变对癌症中miRNA功能的影响。该数据库重点收集miRNA及其靶序列上的突变。另一,数据库还供给了存在miRNA靶序列体细胞突变与肿瘤关联的基因及其参与的通路。
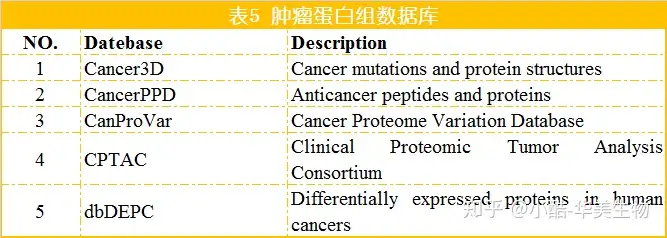
5.肿瘤蛋白组数据库
蛋白是生命活动的重点承担者,蛋白结构变异、蛋白修饰的改变以及蛋白含量的变化等引起细胞的生长和代谢变化是肿瘤出现的要紧原因。
5.1Cancer3D[26]Cancer3D数据库整合了来自TCGA和CCLE的体细胞错义突变信息,在蛋白结构水平上分析其对蛋白功能的影响。该数据库经过e-Driver和e-Drug两种算法,帮忙用户分析突变的分布模式及其与药品活性变化的关系。
5.2CancerPPD[27]CancerPPD是一个抗癌肽(ACPs)和抗癌蛋白的储存库,在设计基于肽的抗癌疗法中非常有用。在CancerPPD中,针对每一个条目,都有其仔细的注释信息,如肽的源自、肽的性质、抗癌活性、N-和C-末端修饰、构象等。除了天然肽,CancerPPD还含有非天然的、经过化学修饰的残基肽和D-氨基酸。CancerPPD还整合了有些基于web的工具,包含重要字搜索、数据浏览、序列和结构类似性搜索。
5.3Cancer Proteome Variation Database(CanProVar)[28]CanProVar数据库整合了来自各样公共资源的蛋白质序列变异信息,重点是癌症关联的变异,CanProVar中的数据重点源自于TCGA、COSMIC、OMIM、HPI等数据库以及有些文献科研。在该数据库中,用户可在网中搜索特定蛋白或某种肿瘤,获取蛋白的突变状况,在结果页面会给出蛋白的基本信息、GO注释以及关联的科研文献。
5.4ClinicalProteomic Tumor Analysis Consortium (CPTAC)[29]CPTAC整合了基因组和蛋白组的数据,旨在识别和描述肿瘤组织和正常组织中的所有蛋白,发掘可做为肿瘤生物标记的候选蛋白。
5.5DbDEPC[30]DbDEPC是一个专门收集肿瘤样本中显现的差异表达蛋白的数据库。在该数据库中,你能够认识你所感兴趣的蛋白质可否在某些癌症中出现了变化。
6.肿瘤关联基因数据库
6.1DriverDBDriverDB收集了来自TCGA、ICGC、TARGET等数据库的海量exome-seq数据,并按照不同方面供给突变信息的可视化。这些可视化结果将有助于用户快速认识驱动基因之间的关系。
6.2Networkof Cancer Genes (NCG)[31]癌症基因网络(NCG)致力于收集关于人工筛选的已知和候选癌症基因的信息。针对每一个基因,用户可得到与该基因关联的功能和疾患注释信息、突变信息、表达谱、miRNA及蛋白互作关系等,还能够可视化miRNA调控关系和蛋白互作网络。
6.3TP53MULTLoad[32]TP53MULTLoad是一个人工收集的相关TP53突变和突变体资源中心,包括了UMDTP53数据库以及与TP53相关的信息。它既能够做为一个容易操作的平面文件,亦能够做为一个新的多平台分析软件,用于分析TP53突变的各个方面。
7.肿瘤与药品数据库
7.1CancerDR[33]耐药性是肿瘤治疗的一大阻碍,药品靶点突变是产生获得性耐药的重点原由之一。对这些药品靶点突变的充分认识将有助于设计有效的个性化治疗。CancerDR是一种针对癌症治疗的个性化药品的尝试。CancerDR收集了148种抗癌药品以及它们在952种细胞系中的药理情况。
7.2CancerResource[34]CancerResource经过文献挖掘以及整合多种数据源的方式收集并发掘了海量化合物及其靶点的信息。经过CancerResource数据库,你能够得到包括化合物与靶标的仔细信息、表达图谱及关联数据源自链接等。
7.3canSAR[35]canSAR整合ArrayExpress、UniProt、COSMIC等11种数据源的数据。它是一个支持癌症转化科研和药品发掘的公共癌症综合知识库。该数据库包括了包含生物学、药理学、化学、结构生物学和蛋白质相互功效网络等多种类型的数据。
7.4Genomics of Drug Sensitivity inCancer (GDSC)[36]GDSC是关于癌症细胞药品敏锐性和药品反应分子标记的数据库,GDSC供给了一个独特的资源,结合了大的药品敏锐性和基因组数据集,以促进发掘新的治疗生物标志物的癌症治疗。该数据库中的癌基因组突变信息包含癌基因点突变、基因扩增与丢失、组织类型以及表达谱等。
7.5Platinum[37]Platinum是一个广泛收集耐药性信息的数据库,是为了科研和理解错义突变对配体与蛋白质组相互功效的影响而研发的。该数据库包括超过1000种蛋白配体复合物的三维结构突变,以及这些突变对其亲和力的影响。Platinum数据库将蛋白质结构突变与配体的亲和力相关起来,有助于科研由突变导致的疾患耐药性。
参考文献
[1] Samur M K, Yan Z, Wang X, et al. canEvolve: A Web Portal for Integrative Oncogenomics [J]. PLOS ONE, 2013, 8.
[2] Gao J, Aksoy B A, Dogrusoz U, et al. Integrative Analysis of Complex Cancer Genomics and Clinical Profiles Using the cBioPortal [J]. Science Signaling, 2013, 6(269): pl1-pl1.
[3] Strausberg R L, Buetow K H, Emmert-Buck M R, et al. The Cancer Genome Anatomy Project: building an annotated gene index [J]. Trends in Genetics Tig, 2000, 16(3): 103-106.
[4] Wilks C, Cline M S, Weiler E, et al. The Cancer Genomics Hub (CGHub): overcoming cancer through the power of torrential data [J]. Database, 2014.
[5] Zhang J, Finney R P, Rowe W, et al. Systematic analysis of genetic alterations in tumors using Cancer Genome WorkBench (CGWB) [J]. Genome Research, 2007, 17(7): 1111-1117.
[6] Forbes S A, Beare D, Gunasekaran P, et al. COSMIC: exploring the world’s knowledge of somatic mutations in human cancer [J]. Nucleic Acids Research, 2015, 43(D1): D805-D811.
[7] Banks R, LopezOtín, Carlos. International network of cancer genome projects [J]. Nature, 2010, 464(7291): 993-998.
[8] Chang K, Creighton C J, Davis C, et al. The Cancer Genome Atlas Pan-Cancer analysis project [J]. Nature Genetics, 2013, 45(10): 1113-1120.
[9] Benz S C, Craft B, Szeto C, et al. The UCSC Cancer Genomics Browser: update 2011 [J]. Nucleic Acids Research, 2013, 43(Database issue): 812-7.
[10] Cai H, Gupta S, Rath P, et al. ArrayMap 2014: An updated cancer genome resource [J]. Nucleic Acids Research, 2014, 43(D1).
[11] Wu T J, Shamsaddini A, Pan Y, et al. A framework for organizing cancer-related variations from existing databases, publications and NGS data using a High-performance Integrated Virtual Environment (HIVE) [J]. Database, 2014, 2014: bau022-bau022.
[12] Scheinin I, Myllykangas S, Borze I, et al. CanGEM: mining gene copy number changes in cancer [J]. Nucleic Acids Research, 2007, 36(Database): D830-D835.
[13] Cao Q, Zhou M, Wang X, et al. CaSNP: a database for interrogating copy number alterations of cancer genome from SNP array data [J]. Nucleic Acids Research, 2011, 39(Database issue): D968.
[14] Timms B. Cancer genome project to start [J]. European Journal of Cancer, 2000, 36(6): 687.
[15] Lv J, Liu H, Su J, et al. DiseaseMeth: a human disease methylation database [J]. Nucleic Acids Research, 2012, 40(Databaseissue): 1030-5.
[16] Baek S J, Yang S, Kang T W, et al. MENT: Methylation and expression database of normal and tumor tissues [J]. Gene, 2013, 518(1): 194-200.
[17] Huang W Y, Hsu S D, Huang H Y, et al. MethHC: a database of DNA methylation and gene expression in human cancer [J]. Nucleic Acids Research, 2015, 43(D1): D856-D861.
[18] He X, Chang S, Zhang J, et al. MethyCancer: the database of human DNA methylation and cancer [J]. Nucleic Acids Research, 2008, 36(Database issue): D836-841.
[19] Kolesnikov N, Hastings E, Keays M, et al. ArrayExpress update--simplifying data submissions [J]. Nucleic Acids Research, 2015, 43(D1): D1113-D1116.
[20] Frenkel-Morgenstern M, Gorohovski A, Vucenovic D, et al. ChiTaRS 2.1--an improved database of the chimeric transcripts and RNA-seq data with novel sense-antisense chimeric RNA transcripts [J]. Nucleic Acids Research, 2015, 43(D1): D68-D75.
[21] Barrett T, Troup D B, Wilhite S E, et al. NCBI GEO: archive for functional genomics data sets - 10years on [J]. Nucleic Acids Research, 2012, 39(D1).
[22] Xie B, Ding Q, Han H, et al. miRCancer: a microRNA-cancer association database constructed by text mining on literature [J]. Bioinformatics, 2013, 29(5): 638-644.
[23] Rhodes D R, Kalyana-Sundaram S, Mahavisno V, et al. Oncomine 3.0: Genes, Pathways, and Networks in a Collection of 18,000 Cancer Gene Expression Profiles [J]. Neoplasia, 2007, 9(2): 166-180.
[24] Wang D, Gu J, Wang T, et al. OncomiRDB: a database for the experimentally verified oncogenic and tumor-suppressive microRNAs [J]. Bioinformatics, 2014, 30(15): 2237-2238.
[25] Bhattacharya A, Ziebarth J D, Cui Y. SomamiR: A database for somatic mutations impacting microRNA function in cancer [J]. Nucleic Acids Research, 2012, 41(Database issue).
[26] Porta-Pardo E, Hrabe T, Godzik A. Cancer3D: understanding cancer mutations through protein structures [J]. Nucleic Acids Research, 2015, 43(D1): D968-D973.
[27] Tyagi A, Tuknait A, Anand P, et al. CancerPPD: a database of anticancer peptides and proteins [J]. Nucleic Acids Research, 2015, 43(D1): D837-D843.
[28] Li J, Duncan D T, Zhang B. CanProVar: a human cancer proteome variation database [J]. Human Mutation, 2010, 31(3): 219-228.
[29] Ellis M J, Gillette M, Carr S A, et al. Connecting genomic alterations to cancer biology with proteomics: The NCI clinical proteomic tumor analysis consortium [J]. Cancer Discovery, 2013, 3(10): 1108-1112.
[30] He Y, Zhang M, Ju Y, et al. dbDEPC 2.0: updated database of differentially expressed proteins in human cancers [J]. Nucleic Acids Research, 2012, 40(D1): D964-D971.
[31] An O, Pendino V, D’Antonio M, et al. NCG 4.0: the network of cancer genes in the era of massive mutational screenings of cancer genomes [J]. Database, 2014, 2014: bau015-bau015.
[32] Leroy B, Fournier J L, Ishioka C, et al. The TP53 website: an integrative resource centre for the TP53 mutation database and TP53 mutant analysis [J]. Nucleic Acids Research, 2013, 41(Database issue): D962.
[33] Kumar R, Chaudhary K, Gupta S, et al. CancerDR: Cancer Drug Resistance Database [J]. Scientific Reports, 2013, 3: 1445.
[34] Ahmed J, Meinel T, Dunkel M, et al. CancerResource: a comprehensive database of cancer-relevant proteins and compound interactions supported by experimental knowledge [J]. Nucleic Acids Research, 2011, 39(Database issue): 960-7.
[35] Bulusu K C, Tym J E, Coker E A, et al. canSAR: updated cancer research and drug discovery knowledgebase [J]. Nucleic Acids Research, 2014, 42(D1): D1040-D1047.
[36] Yang W, Soares J, Greninger P, et al. Genomics of Drug Sensitivity in Cancer (GDSC): a resource for therapeutic biomarker discovery in cancer cells [J]. Nucleic Acids Research, 2013, 41(Database issue): D955.
[37] Pires D E V, Blundell T L, Ascher D B. Platinum: A database of experimentally measured effects of mutations on structurally defined protein-ligand complexes [J]. Nucleic Acids Research, 2014, 43(D1).
肿瘤数据库合辑(附网址)EXCEL免费下载,
关注“武汉华美生物”官方微X,后台回复: “肿瘤数据库”
—END—
——华美生物·让研究变得有温度! ——
●●●保藏|高分SCI论文必须指南
保藏|15个论文必须网汇总
资源|这几个下载文献资料的网,非常强大!
工具|研究人都pick的小工具,计算3秒搞定!
Nature重磅:猎杀癌细胞基因名单颁布!揭秘628个抗癌药品靶点
必读|神刊CA(IF=244.59)再次发帖-2019美国癌症数据速读
必读|影响因子排名第1(IF244.59)神刊CA-2018全世界癌症最新统计数据
必读|WHO颁布最新预防痴傻症指南-怎样早预防?
央视报告|华中地区首个膜蛋白诺贝尔奖工作站落户武汉华美生物
新品推介|高活性EGFR重组蛋白
新品推介|新兴治疗靶点BCMA
| 

 发表于 2024-6-14 13:06:20
发表于 2024-6-14 13:06:20